/** * 默认的初始容量为 16 * The default initial capacity - MUST be a power of two. */ staticfinalintDEFAULT_INITIAL_CAPACITY=1 << 4; // aka 16
/** * 最大容量 * The maximum capacity, used if a higher value is implicitly specified * by either of the constructors with arguments. * MUST be a power of two <= 1<<30. */ staticfinalintMAXIMUM_CAPACITY=1 << 30;
/** * 默认的负载因子 * The load factor used when none specified in constructor. */ staticfinalfloatDEFAULT_LOAD_FACTOR=0.75f;
/** * 当桶上的结点数大于等于这个值会转化为红黑树 * The bin count threshold for using a tree rather than list for a * bin. Bins are converted to trees when adding an element to a * bin with at least this many nodes. The value must be greater * than 2 and should be at least 8 to mesh with assumptions in * tree removal about conversion back to plain bins upon * shrinkage. */ staticfinalintTREEIFY_THRESHOLD=8;
/** * 当桶上的结点数小于等于这个值会转化为链表 * The bin count threshold for untreeifying a (split) bin during a * resize operation. Should be less than TREEIFY_THRESHOLD, and at * most 6 to mesh with shrinkage detection under removal. */ staticfinalintUNTREEIFY_THRESHOLD=6;
/** * 桶中结构转换为红黑树对应的table的最小容量 * The smallest table capacity for which bins may be treeified. * (Otherwise the table is resized if too many nodes in a bin.) * Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts * between resizing and treeification thresholds. */ staticfinalintMIN_TREEIFY_CAPACITY=64;
/** * 存放元素的数组,容量总是2的幂次方 * The table, initialized on first use, and resized as * necessary. When allocated, length is always a power of two. * (We also tolerate length zero in some operations to allow * bootstrapping mechanics that are currently not needed.) */ transient Node<K,V>[] table;
/** * 存放具体元素的值 * Holds cached entrySet(). Note that AbstractMap fields are used * for keySet() and values(). */ transient Set<Map.Entry<K,V>> entrySet;
/** * 存放元素的个数,不等于数组的长度 * The number of key-value mappings contained in this map. */ transientint size;
/** * 每次扩容和更改map结构的计数器 * The number of times this HashMap has been structurally modified * Structural modifications are those that change the number of mappings in * the HashMap or otherwise modify its internal structure (e.g., * rehash). This field is used to make iterators on Collection-views of * the HashMap fail-fast. (See ConcurrentModificationException). */ transientint modCount;
/** * 阈值(容量 * 负载因子),当实际大小超过阈值时,会触发扩容 * The next size value at which to resize (capacity * load factor). */ int threshold;
/** * 负载因子 * The load factor for the hash table. */ finalfloat loadFactor;
/** * 指定容量大小和负载因子的构造函数 * Constructs an empty <tt>HashMap</tt> with the specified initial * capacity and load factor. */ publicHashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) thrownewIllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) thrownewIllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; // 初始容量暂时存放到threshold,在resize方法中再赋值给newCap进行table的初始化 this.threshold = tableSizeFor(initialCapacity); }
/** * 指定容量大小的构造函数 * Constructs an empty <tt>HashMap</tt> with the specified initial * capacity and the default load factor (0.75). */ publicHashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); }
/** * 默认构造器 * Constructs an empty <tt>HashMap</tt> with the default initial capacity * (16) and the default load factor (0.75). */ publicHashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted }
/** * 包含另一个Map的构造函数 * Constructs a new <tt>HashMap</tt> with the same mappings as the * specified <tt>Map</tt>. The <tt>HashMap</tt> is created with * default load factor (0.75) and an initial capacity sufficient to * hold the mappings in the specified <tt>Map</tt>. */ publicHashMap(Map<? extends K, ? extends V> m) { this.loadFactor = DEFAULT_LOAD_FACTOR; putMapEntries(m, false); }
/** * Associates the specified value with the specified key in this map. * If the map previously contained a mapping for the key, the old * value is replaced. */ public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
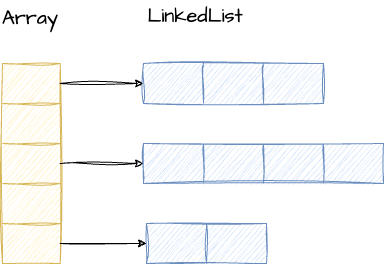
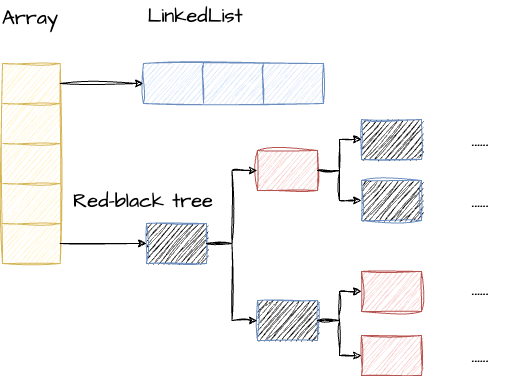
.png)