《MySQL是怎样运行的 —— 从跟上理解MySQL》—— 第一章
一、MySQL的C/S架构
MySQL的运行过程是:MySQL服务器程序直接与要存储的数据打交道,多个客户端程序可以连接到这个服务器程序,向服务器程序发送数据变更请求,然后服务器程序根据这些请求,对存储的数据进行相应的处理。
MySQL的日常使用场景:
- 启动MySQL服务器程序
- 启动MySQL客户端程序,并链接到服务器程序
- 在客户端程序中输入命令,并将其作为请求发送给服务器程序。服务器程序在收到请求后,根据请求的内容来操作具体的数据,并将结果返回给客户端。
运行过程中的MySQL服务器程序和客户端程序本质上都是计算机中的进程,其中代表MySQL服务器程序的进程成为MySQL数据库实例(Instance)。
二、安装MySQL
2.1 通用型
直接前往官网下载对应的版本即可,点击前往下载
2.2 Brew安装
尝试使用HomeBrew进行安装
1)安装MySQL:在终端中输入以下命令
brew install mysql |
如果想要指定版本,比如MySQL8,可以这么干:
注意
mysql@8.0是安装 MySQL 8 的包名称
2)启动MySQL服务器:在终端中输入以下命令并按下回车键
brew services start mysql |
3)可以使用以下命令检查 MySQL 服务器的运行状态
brew services list |
如果输出中显示 "mysql" 为 "started" 状态,则表示 MySQL 服务器已成功启动。
2.3 Linux安装
参考文章:How to install MySQL on Linux
2.4 Docker安装
示例命令:
docker run -d --name mysql-container \ |
三、启动MySQL
3.1 类UNIX系统启动MySQL
在类UNIX系统中,用来启动MySQL服务器程序的可执行文件有很多,大部分都位于MySQL安装目录的bin目录下:
➜ ~ ls /usr/local/mysql/bin |
1)mysqld
mysqld可执行文件就表示MySQL服务器程序,运行这个可执行文件就可以直接启动一个MySQ服务器进程。
2)mysqld_safe
mysqld_safe是一个启动脚本,它会间接调用mysqld并持续监控服务器的运行状态。当服务器进程出现错误时,它还可以帮助重启服务器程序。
除此之外,使用mysqld_safe启动MySQL服务器程序时,它会将服务器程序的出错信息和其他诊断信息输出到错误日志,方便后期查找错误发生的原因。
出错日志默认写到一个以
.err为扩展名的文件中,该文件位于MySQL的数据目录中。
192.168.0.100.err
192.168.0.101.err
CodeJuzideMacBook-Pro.local.err
mysqld.local.err
3)mysql.server
mysql.server也是一个启动脚本,它会间接调用mysqld_safe。在执行mysql.server时,后面添加start参数就可以启动服务器程序了(推荐的启动方式):
mysql.server start |
mysql.server其实是一个链接文件,对应的实际文件是/usr/local/mysql/support-files/mysql.server
/usr/local/mysql/support-files
➜ support-files ls
mysql-log-rotate mysql.server mysqld_multi.server
3.2 在Windows系统中启动MySQL
1)手动启动
在MySQL的安装目录的bin目录下存在一个mysqld的可执行文件,在命令行输入mysqld或者直接双击该文件,就可以启动MySQL服务器程序了。
如果没有启动成功,可以使用
mysqld --console命令来启动服务器程序,根据输出的日志信息来定位错误。
2)以服务的方式启动
将MySQL注册为一个Windows服务,交由操作系统来帮助我们管理。
把某个程序注册为Windows服务的方式:
-manual属性表示Windows系统启动的时候不自动启动该服务,否则会自动启动- 服务名可以省略,使用默认的服务名即可
注册MySQL为服务(服务名默认就是MySQL):
"C:\Program Files\MySQL\MySQL Server 8.0\bin\mysqld" --install MySQL |
在将mysqld注册为服务后,启动MySQL就变得很简单了:
net start MySQL |
同理,关闭MySQL:
net stop MySQL |
四、启动MySQL客户端程序
成功启动完MySQL服务器程序后,就可以启动MySQL客户端程序连接到这个服务器了。
此处重点关注bin目录下的可执行文件mysql,通过这个可执行文件,我们可以与服务器程序交互,也就是发送请求并接收服务器的处理结果。
启动这个可执行文件需要一些参数:
-h, --host=<hostname>:指定MySQL服务器的主机名或IP地址。-P, --port=<port>:指定MySQL服务器的端口号。-u, --user=<username>:指定连接到MySQL服务器时使用的用户名。-p, --password[=<password>]:提示输入连接到MySQL服务器时使用的密码。如果指定了密码,可以直接在参数后面提供密码值,或者在不指定密码值的情况下,等待用户输入密码。-D, --database=<dbname>:连接到MySQL服务器后,默认使用的数据库。--ssl-mode=<mode>:指定与服务器之间的SSL连接的模式,可以是"DISABLED"(禁用SSL,默认值)、"REQUIRED"(要求使用SSL)或"VERIFY_CA"(要求使用SSL,并验证服务器端的证书)。-h, --help:显示MySQL命令的帮助信息,包括可用参数和使用示例。
上述参数可以组合使用,比如:
mysql -h主机名 -u用户名 -p密码 |
连接时候的注意事项:
- 不要在一行命令中输入密码
- 非要在一行命令中输入密码,可以像这样:
mysql -hlocalhost -uroot -p123456,不要加上空白字符即可 - mysql的参数顺序没有硬性规定
- 如果服务器程序和客户端程序在一台机器上,可以省略
-h参数 - 如果使用的是类UNIX系统,省略
-u参数后,会将登录操作系统的用户名当做MySQL的用户名去处理
五、客户端与服务器连接的过程
运行中的服务器程序和客户端程序本质上都是计算机上的一个进程,所以客户端进程向服务器进程发出请求并得到响应本质上是一个进程间通信的过程。MySQL支持几种客户端进程和服务器进程的通信方式。
5.1 TCP/IP
实际场景中,数据库的服务器进程和客户端进程可能运行在不同的主机中,它们之间必须通过网络进行通信。MySQL采用TCP作为服务器和客户端之间的网络通信协议。网络中的其他进程可以采用ip + port的方式与这个进程建立连接。
MySQL服务器会在启动的时候默认申请3306端口,之后在这个端口上等待客户端进程的连接。
如果3306端口号被占用了,或者单纯的想自定义端口号,可以在启动服务器程序的命令行中添加-P参数指定端口号,比如:
mysqld -P3307 |
随后客户端进程想要通过TCP/IP网络与服务器进程进行通信,我们需要增加-P参数指定端口号,比如:
mysql -h127.0.0.1 -uroot -P3307 -p |
另外的形式分别是:
- 命令管道和共享内存
- UNIX域套接字
六、服务器处理客户端请求
无论客户端进程和服务器进程之间采用什么方式通信,最后实现的效果都是客户端进程向服务器进程发送一段文本(MySQL语句),服务器进程处理后再向客户端进程返回一段文本(处理结果)。这期间服务器进程做了什么呢?大致过程如下图:
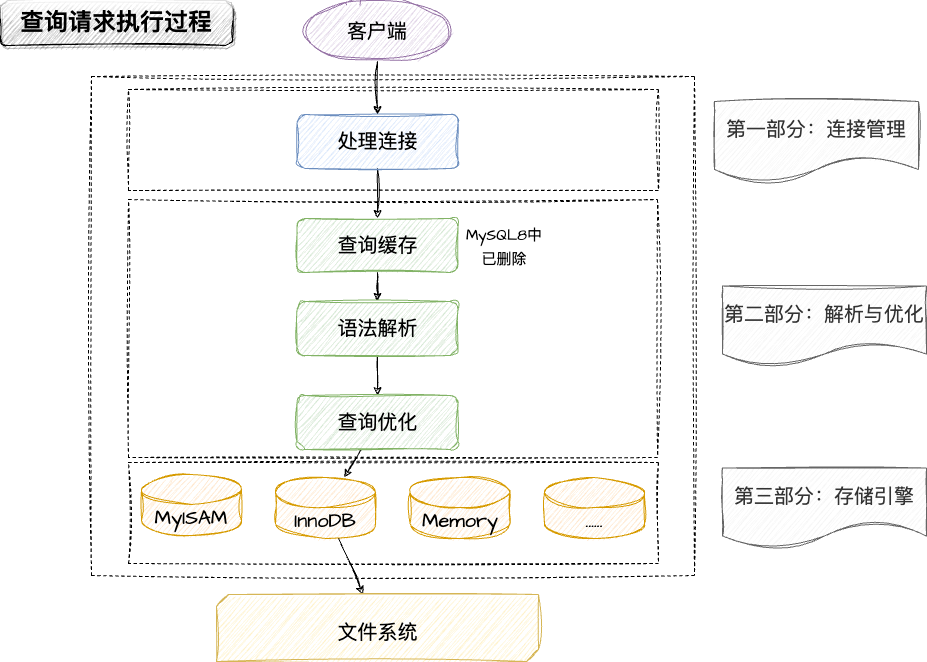
从上图可以看出,服务器程序在处理客户端的查询请求的时候,大致需要分成三个部分:连接管理、解析与优化、存储引擎。
6.1 连接管理
客户端进程可以采用TCP/IP等形式与服务器进程建立连接。
每当有一个客户端进程连接到服务器进程的时候,服务器进程都会创建一个线程专门处理与该客户端的交互;当该客户端退出的时候,会与服务器进程断开连接,但是服务器进程并不会立即把与该客户端的进程销毁,而是将该线程缓存起来,在另一个新的客户端再进行连接时,把这个缓存的线程分配给该新的客户端。
这么做就不用频繁地创建和销毁线程,从而节省了开销。—— 池化技术,线程池管理。
这期间还涉及到连接数量的管理、客户端信息的校验认证、传输层安全性保证等等流程。
6.2 解析与优化
6.2.1 查询缓存
MySQL服务器程序处理查询请求时,会将处理好的查询请求和结果缓存起来,如果下一次有同样的请求过来,直接在缓存中获取就好了,不需要再去底层的表中查找了,该查询缓存可以在不同的客户端进程之间共享。
但是,如果两个查询请求有任何字符上的不同,都会导致缓存不会命中。除此之外,如果查询请求中包含某些系统函数、用户自定义变量和函数、系统表,这个请求也不会被缓存。
既然是缓存,就会有失效的时候。MySQL中的缓存系统会检测涉及的每张表,只要该表的结构或者数据被修改,则与该表有关的所有查询缓存都会变得无效,并从查询缓存中删除。
虽然查询缓存有时可以提高系统性能,但是需要额外的精力去维护这块的开销。从MySQL5.7.20开始,不再推荐使用查询缓存,在MySQL8.0中已经删除了查询缓存。
6.2.2 语法解析
这一阶段,MySQL服务器程序需要对客户端发送的请求(一段文本)进行分析,判断请求的语法是否正确,然后从文本中将要查询的表、各种查询条件都提取出来放到MySQL服务器内部使用的一些数据结构上。
6.2.3 查询优化
在语法解析之后,服务器程序获得了需要的信息,比如查询的表是什么、查询条件是什么等等。但是,光有这些是不够的,因为我们写的SQL语句执行起来效率可能不是很高,MySQL的优化程序会对我们的语句做一些优化,比如表达式简化、子查询转为连接等等一系列操作。
优化的结果是生成一个执行计划,这个执行计划表明了应该使用哪些索引执行查询,以及表之间的连接顺序结构等等。
我们可以使用EXPLAIN语句来查看某个语句的执行计划。
6.3 存储引擎
上述的一系列流程都没有真正地去访问真实的表中的数据。
MySQL服务器把数据的存储和提取操作都封装到了一个名为存储引擎的模块中。表是由一行一行的记录组成的,但这只是一个逻辑上的概念,在物理上如何标记记录,怎么从表中读取数据,以及怎么把数据写入具体的物理存储器上,都是粗糙农户引擎负责的事情。
为了实现不同的功能,MySQL提供了各式各样的存储引擎,不同的存储引擎管理的表可能可能有不同的存储结构,采用的存取算法也可能不同。
存储引擎以前叫做表处理器。其功能就是接收上层传下来的指令,然后对表中的数据进行读取或者写入操作。
为了方便管理,我们将MySQL服务器处理请求的过程简单地划分为server层和存储引擎层。
- server层负责:连接管理、查询缓存、语法解析、查询优化这些并不涉及真实数据存取的功能
- 存储引擎层负责:存取真实数据的功能
不同的存储引擎为server层提供统一的调用接口,其中包含几十个用途不同的底层函数。
=> 总结下,server层完成了查询优化之后,只需要按照生成的执行计划调用底层存储引擎提供的接口获取到数据后返回给客户端就好了。
📢需要注意的是,server层和存储引擎层交互时,一般是以记录为单位的。
【🌰栗子】以SELECT语句为例,server层根据执行计划先向存储引擎层取一条记录,然后判断是否符合WHERE条件;如果符合,就发送给客户端,否则跳过该记录,然后继续向存储引擎索要下一条记录;以此类推。
七、常用的存储引擎
- InnoDB(MySQL默认的存储引擎)
- MyISAM
- Memory
八、存储引擎的一些操作
8.1 查看当前服务器程序支持的存储引擎
命令:
SHOW ENGINES; |
调用效果:
mysql> SHOW ENGINES; |
1)Support:代表该存储引擎是否可用,DEFAULT值代表当前服务器程序的默认存储引擎
2)Comment:对存储引擎的描述
3)Transactions:代表该存储引擎是否支持事务处理
4)XA:代表该存储引擎是否支持分布式事务
5)Savepoints:代表该存储引擎是否支持事务的部分回滚
8.2 设置表的存储引擎
1、创建表的时候指定存储引擎
如果在创建表的语句中没有指定表的存储引擎,那么就会使用默认的存储引擎InnoDB。显示指定命令:
CREATE TABLE table_name ( |
【eg】
CREATE TABLE `engine_demo_table` ( |
2、修改表的存储引擎
如果表已经建好,可以使用下列语句来修改表的存储引擎:
ALTER TABLE table_name ENGINE = engine_name; |
【eg】
ALTER TABLE `engine_demo_table` ENGINE = InnoDB; |
结果:
mysql> ALTER TABLE `engine_demo_table` ENGINE = InnoDB; |
查看engine_demo_table表结构:
SHOW CREATE TABLE `engine_demo_table`\G; |
结果:
mysql> SHOW CREATE TABLE `engine_demo_table`\G; |
该表的存储引擎已经修改成了InnoDB了。