问题:如何改进 LRU 算法?
传统 LRU 算法存在的问题:
- 「预读失效」导致缓存命中率下降
- 「缓存污染」导致缓存命中率下降
那么 MySQL 和 Linux 是通过改进 LRU 算法来避免这两个问题导致的缓存命中率下降的。
Redis 是通过实现 LFU 算法来避免因为「缓存污染」导致的缓存命中率下降问题的。
缓存在哪里?
Linux 的缓存
在应用程序读取文件数据的时候,Linux 会对读取的文件数据进行缓存,缓存的位置就是在文件系统的 Page Cache 中。
Page Cache 在内存中,内存访问速度比磁盘访问快很多,下一次读取如果命中缓存就不需要进行磁盘 I/O 了,命中缓存就可以直接返回数据了。
MySQL 的缓存
MySQL 的数据是存储在磁盘里面的,为了提升数据库的读写性能,InnoDB 存储引擎在内存中开辟了 Buffer Pool,有了 Buffer Pool 之后的数据操作发生了微妙的变化:
- 当读取数据时,如果数据存在于 Buffer Pool 中,客户端就会直接读取 Buffer Pool 中的数据,否则再从磁盘中去读取;
- 当修改数据时,如果数据存在于 Buffer Pool 中,首先修改 Buffer Pool 中数据所在的页,然后将其标记为脏页,最后由后台线程将脏页刷盘。
传统 LRU 算法存在的问题
不论是 Page Cache,还是 Buffer Pool,空间都是有限的,并不能够无限制的缓存数据。正因为如此,我们才需要将一些热点数据缓存起来,对于一些冷数据希望可以在某些时机淘汰出缓存,从而保证不会因为内存满了无法缓存新的数据,同时还能保证热点数据常驻内存。
要实现这个需求,就需要一些内存管理算法,像 FIFO、LRU、LFU 等等。这里介绍 LRU 算法。
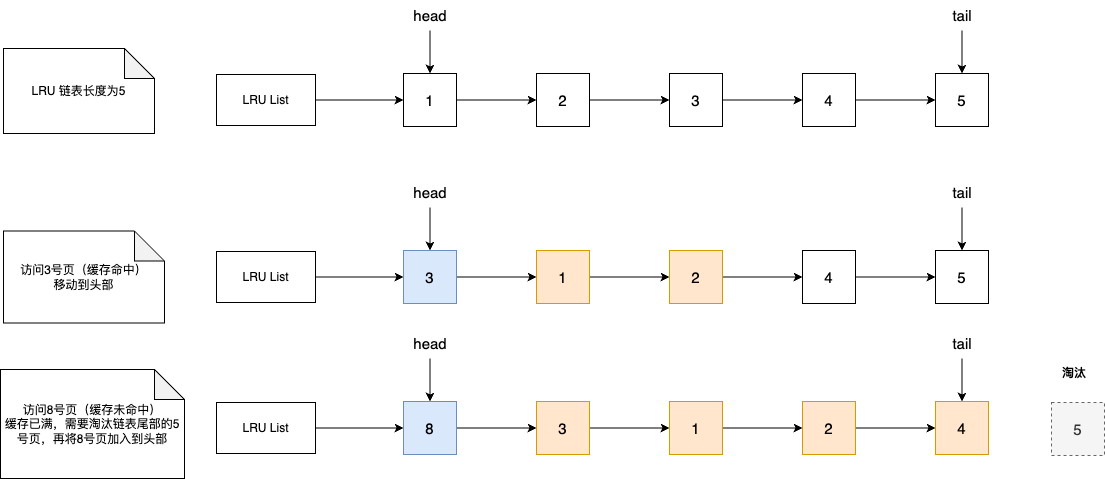
LRU 算法一般使用「链表」作为数据结构来实现,链表头部的数据时最近使用的,链表尾部是最久没有被使用的,当空间不足时,就淘汰最久没被使用的节点,也就是链表末尾的数据,从而腾出内存空间。
⚠️注意:Linux 和 MySQL 的基本数据单位都是页,所以,此处一个节点就代表一个页的数据。
传统的 LRU 算法:
- 当访问的页在内存中,直接将该页对应的 LRU 链表节点移动到链表头部;
- 当访问的页不在内存中,除了要把该页放入到 LRU 链表的头部,还需要淘汰 LRU 链表尾部的页。
然后传统的 LRU 链表没有被 Linux 和 MySQL 采用,因为其存在一些问题:
- 预读失效
- 缓存污染
上述问题都会导致缓存命中率下降。
如何解决预读失效?
预读机制
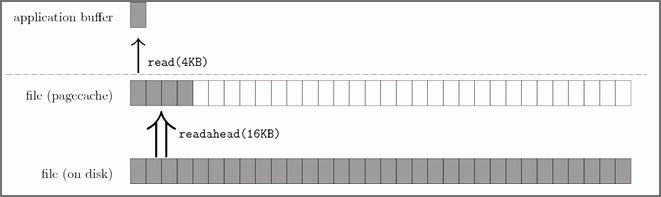
上图中,应用程序利用 read syscall 读取 4KB 的数据,内核会使用预读机制读取 16KB 的数据,也就是通过一次磁盘顺序读将多个 Page 数据装载进 Page Cache。这样下次读取 4KB 之后的数据事,直接在 Page Cache 中读取即可,不需要进行磁盘 I/O。
因此,预读机制带来的好处就是减少了磁盘 I/O 次数,提高系统磁盘 I/O 吞吐量。
MySQL InnoDB存储引擎的 Buffer Pool 也会进行预读,MySQL 从磁盘加载数据页时,会提前把它相邻的页一并加载进来,目的也是为了减少磁盘 I/O。
预读失效带来的问题
如果这些被提前加载进来的页并没有访问,这就是预读失效,即之前做的预读操作是无效的。
当使用传统的 LRU 算法时,这些预读页会被放置在 LRU 链表头部,而当内存不足时,还需要将链表尾部的页淘汰掉。如果这些预读页一直不被访问,就会出现不会被访问的预读页占用了 LRU 链表前排的位置,而末尾淘汰的页可能是热点数据,这样就大大降低了缓存命中率。
如何避免预读失效带来的影响?
首先不能够因为预读会失效,就将预读机制剔除,因为在大部分情况下,空间局部性原理依然成立。
思想
目标:让预读页在内存中的停留时间尽可能短,让真正被访问的页移动到 LRU 链表的头部,从而保证热点数据在内存中停留的时间尽可能的长。
思想:将数据分为冷数据和热数据,分别进行 LRU。
- Linux 实现了两个 LRU 链表:活跃 LRU
链表(
active_list)和 非活跃 LRU 链表(inactive_list); - MySQL InnoDB 存储引擎将一个 LRU 链表划分成两个区域:young 区域和 old 区域。
Linux 解决方案
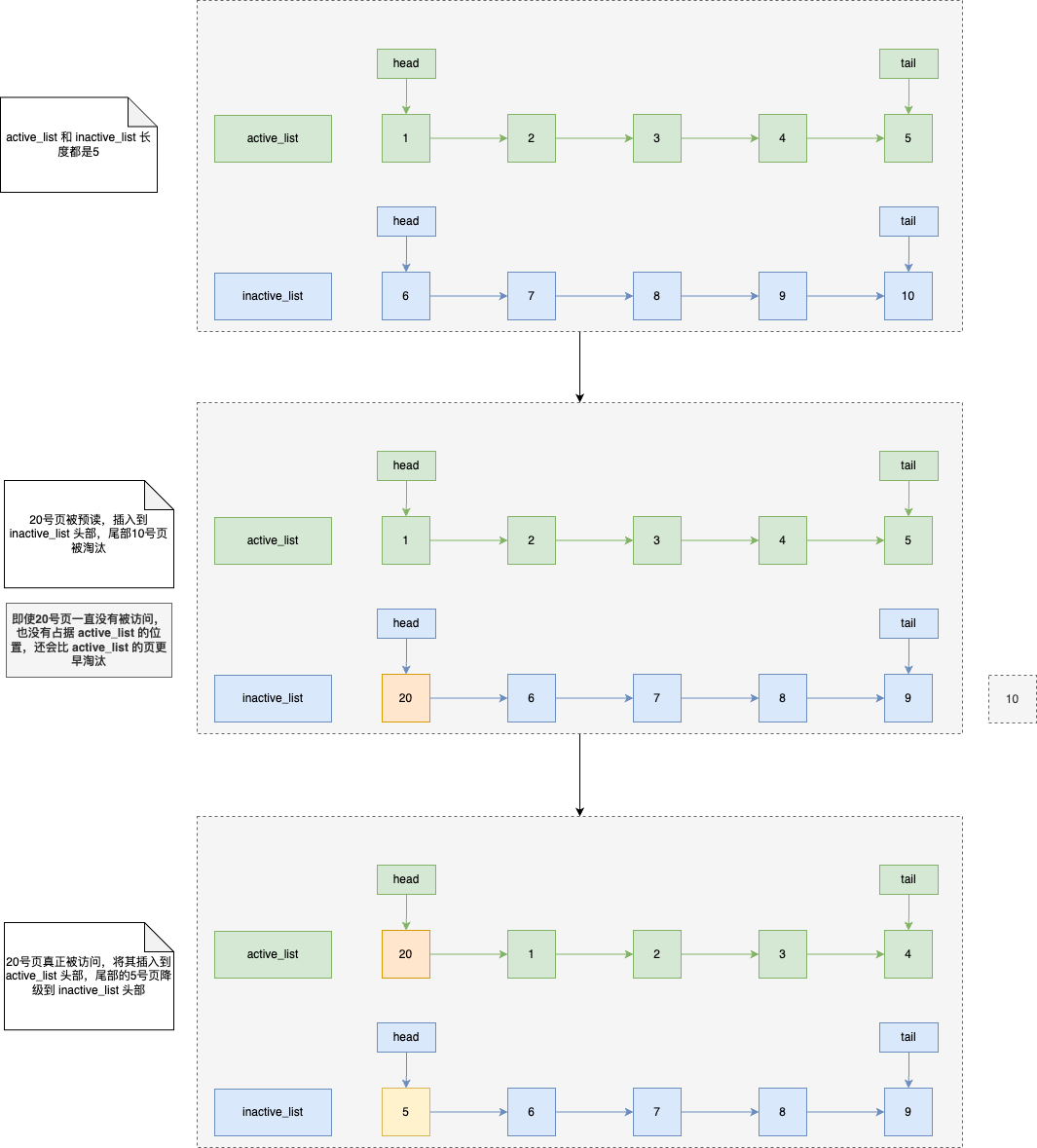
Linux 实现的两个 LRU 链表:
active_list:活跃内存页链表,存放最近被访问过(活跃)的内存页;inactive_list:不活跃内存页链表,存放很少被访问(非活跃)的内存页。
Linux的做法是预读页只需要加入到 inactive_list 区域到头部,当预读页真正被访问时,才将该页插入到 active_list 头部。这样即使预读页一直没有被访问,也不会影响 active_list 中的热点数据。
MySQL 解决方案
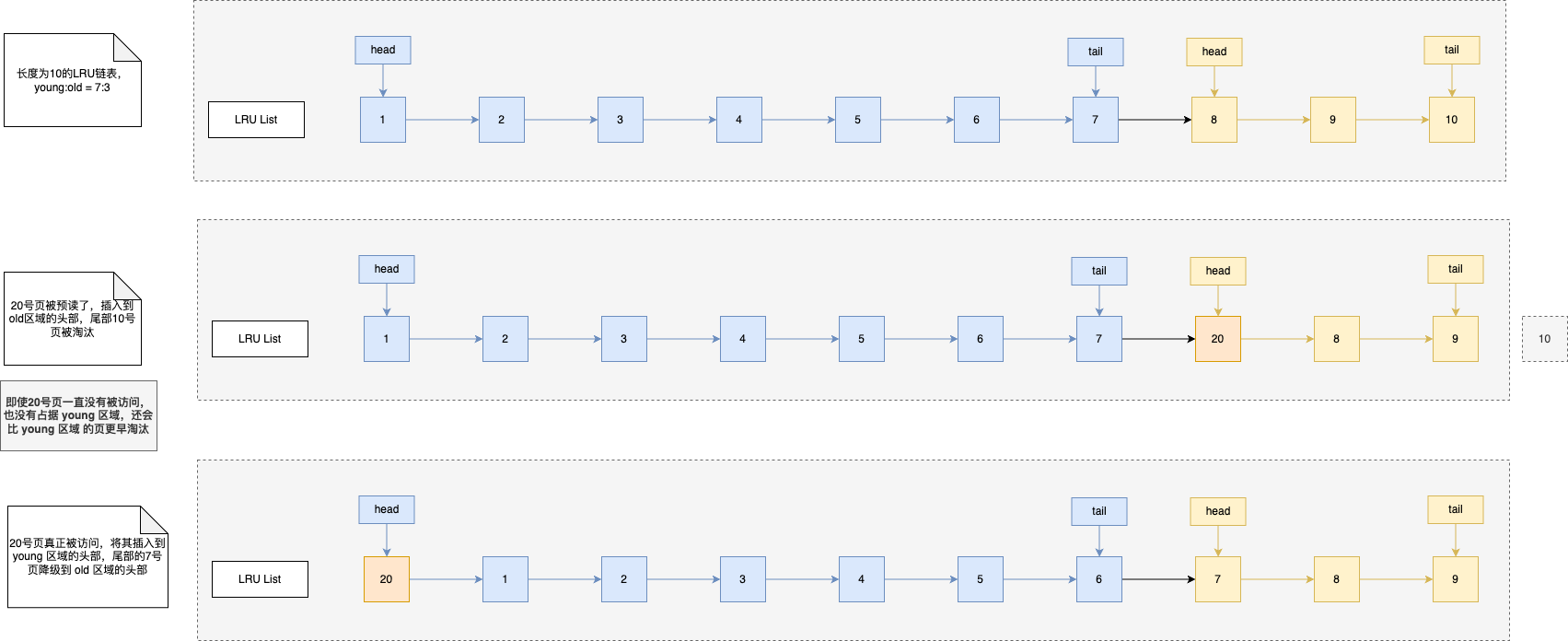
MySQL 的 InnoDB 存储引擎是在一个 LRU 链表上划分出两个区域:
- young 区域:LRU 链表的前半部分,存放热点数据
- old 区域:LRU 链表的后半部分,存放非热点数据和预读数据
二者的默认比例是 63:37,可以自行调整。
划分出两个区域后,预读的页只需要添加到 old 区域的头部,当预读页真正被访问到的时候,才将该页插入到 young 区域到头部。如果预读的页一直没有被访问,就会从 old 区域移除,不会影响 young 区域的热点数据。
如何解决缓存污染?
缓存污染
Linux 和 MySQL 使用改进之后的 LRU 算法,避免了预读失效的问题,但是如果升级到热点区域的门槛太低,还会存在缓存污染的问题。
比如在批量读取数据的时候,由于大量的数据被访问一次就会被加入到热点区域,那之前缓存的热点数据都被降级到非热点区域或者被淘汰,若这些数据在很长一段时间不被访问的话,整个 LRU 链表热点区域就被污染了。
缓存污染带来的问题
缓存污染会淘汰大量的热点数据,那么这些热点数据很快又会被访问,由于此时缓存未命中,就会产生大量的磁盘 I/O,系统性能就会急剧下降。
在 MySQL 中,当某一个 SQL 语句扫描了大量的数据时,在 Buffer Pool 空间有限的情况下,可能会将 Buffer Pool 里的所有页都替换出去,导致大量热数据被淘汰了,等这些热数据被再次访问的时候,由于缓存未命中,就会产生大量的磁盘I/O,MySQL 性能就会急剧下降。
⚠️注意:MySQL 的缓存污染问题并不只是查询语句查询出大量的数据才出现,即使查询出来的数据集很小,也可能会造成缓存污染。
比如,在一个数据量非常大的表中,执行了需要全表扫描的语句,那么就有可能会出现:
- 从磁盘读取页数据加入到 old 区域头部;
- 当从该页读取记录时,会将该页插入到 young 区域的头部;
- 匹配查询条件,符合条件就加入到结果集;
- 重复上述步骤,直到扫描完表中的所有记录。
总结下来就是说,一条SQL会访问很多的页,这些页被预读后很快被访问,导致 young 区域被污染。
如何避免缓存污染造成的影响?
思想
产生上述缓存污染的问题的根源就是数据升级到热点区域的门槛太低。因此,只需要提高门槛,就能够有效的保证热点区域的数据不会被轻易替换掉。
Linux 解决方案
当内存页被访问第二次的时候,才会将该页从 inactive_list 升级到 active_list 中。
MySQL 解决方案
当内存页被访问第二次时,并不会马上将该页从 old区域升级到 young区域,因为还需要进行停留在 old区域时间的判断:
- 如果第二次的访问时间和第一次的访问时间在1s(默认值)内,那么该页就不会从 old区域升级到 young区域;
- 如果第二次的访问时间和第一次的访问时间超过1s,才会将该页从 old区域升级到 young区域。
这样即使在批量读取数据时,如果这些大量数据只会被访问一次,也不会被升级到热点区域,也就不会造成热点区域的污染。
总结
1)解决「预读失效」的问题核心:设置热点区域和非热点区域;
2)解决「缓存污染」的问题核心:提高预读页升级到热点区域的门槛。