什么是 TIME_WAIT
「TCP 四次挥手过程」
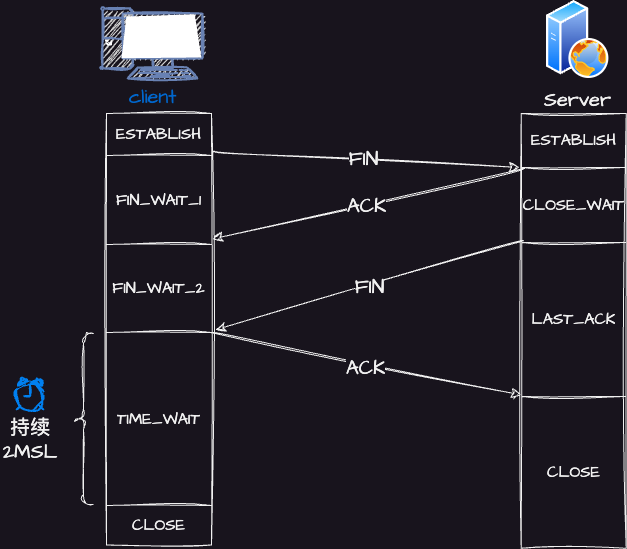
- 客户端打算关闭连接,此时会发送一个 TCP 首部
FIN标志位被置为1的报文,也即FIN报文,之后客户端进入FIN_WAIT_1状态; - 服务端收到该报文后,就向客户端发送
ACK应答报文,接着服务端进入CLOSE_WAIT状态; - 客户端收到服务端的
ACK应答报文后,之后进入FIN_WAIT_2状态; - 等待服务端处理完数据后,也向客户端发送
FIN报文,之后服务端进入LAST_ACK状态; - 客户端收到服务端的
FIN报文后,回一个ACK应答报文,之后进入TIME_WAIT状态; - 服务端收到了
ACK应答报文后,就进入了CLOSE状态,至此服务端已经完成连接的关闭; - 客户端在经过
2MSL一段时间后,自动进入CLOSE状态,至此客户端也完成连接的关闭。
⚠️注意:主动关闭连接的,才有 TIME_WAIT 状态。
为什么 TIME_WAIT 等待的时间是 2MSL?
MSL (Maximum Segment Lifetime),报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
因为 TCP 基于是 IP 协议的,而 IP 头中有一个
TTL字段,是 IP 数据报可以经过的最大路由数,每经过一个处理路由器此值就减 1,当此值为 0 则数据报将被丢弃,同时发送 ICMP 报文通知源主机。MSL 与 TTL 的区别: MSL 的单位是时间,而 TTL 是经过路由跳数。所以 MSL 需要大于等于 TTL 消耗为 0 的时间,以确保报文已被自然消亡。
TTL 的值一般是 64,Linux 将 MSL 设置为 30 秒,意味着 Linux 认为数据报文经过 64 个路由器的时间不会超过 30 秒,如果超过了,就认为报文已经消失在网络中了。
TIME_WAIT 等待 2 倍的
MSL,比较合理的原因是网络中可能存在来自发送方的数据包,当这些发送方的数据包被接收方处理后又会向对方发送响应,所以一来一回需要等待
2 倍的时间。
可以看出 2MSL时长
这其实是相当于至少允许报文丢失一次。比如,若 ACK 在一个
MSL 内丢失,这样被动方重发的 FIN 会在第 2 个 MSL
内到达,TIME_WAIT 状态的连接可以应对。
为什么不是 4 或者 8 MSL 的时长呢?
想象一个丢包率达到百分之一的糟糕网络,连续两次丢包的概率只有万分之一,这个概率太小,因此忽略它比解决它更具性价比。
2MSL 的时间是从客户端接收到 FIN 后发送 ACK
开始计时的。如果在 TIME-WAIT 时间内,因为客户端的 ACK
没有传输到服务端,客户端又接收到了服务端重发的 FIN 报文,那么
2MSL 时间将重新计时。
为什么需要 TIME_WAIT 状态?
原因:
- 防止历史连接中的数据,被后面相同四元组的连接错误的接收;
- 保证「被动关闭连接」的一方,能被正确的关闭。
原因一:防止历史连接中的数据,被后面相同的四元组的连接错误的接收
序列号(SEQ)和初始序列号(ISN):
- 序列号,是 TCP 一个头部字段,标识了 TCP 发送端到 TCP 接收端的数据流的一个字节,因为 TCP 是面向字节流的可靠协议,为了保证消息的顺序性和可靠性,TCP 为每个传输方向上的每个字节都赋予了一个编号,以便于传输成功后确认、丢失后重传以及在接收端保证不会乱序。序列号是一个 32 位的无符号数,因此在到达 4G 之后再循环回到 0。
- 初始序列号,在 TCP 建立连接的时候,客户端和服务端都会各自生成一个初始序列号,它是基于时钟生成的一个随机数,来保证每个连接都拥有不同的初始序列号。初始化序列号可被视为一个 32 位的计数器,该计数器的数值每 4 微秒加 1,循环一次需要 4.55 小时。
序列号和初始化序列号并不是无限递增的,会发生回绕为初始值的情况,这意味着无法根据序列号来判断新老数据。
现在假设 TIME_WAIT 没有等待时间或者时间过短,被延迟的数据包到达之后会发生什么?
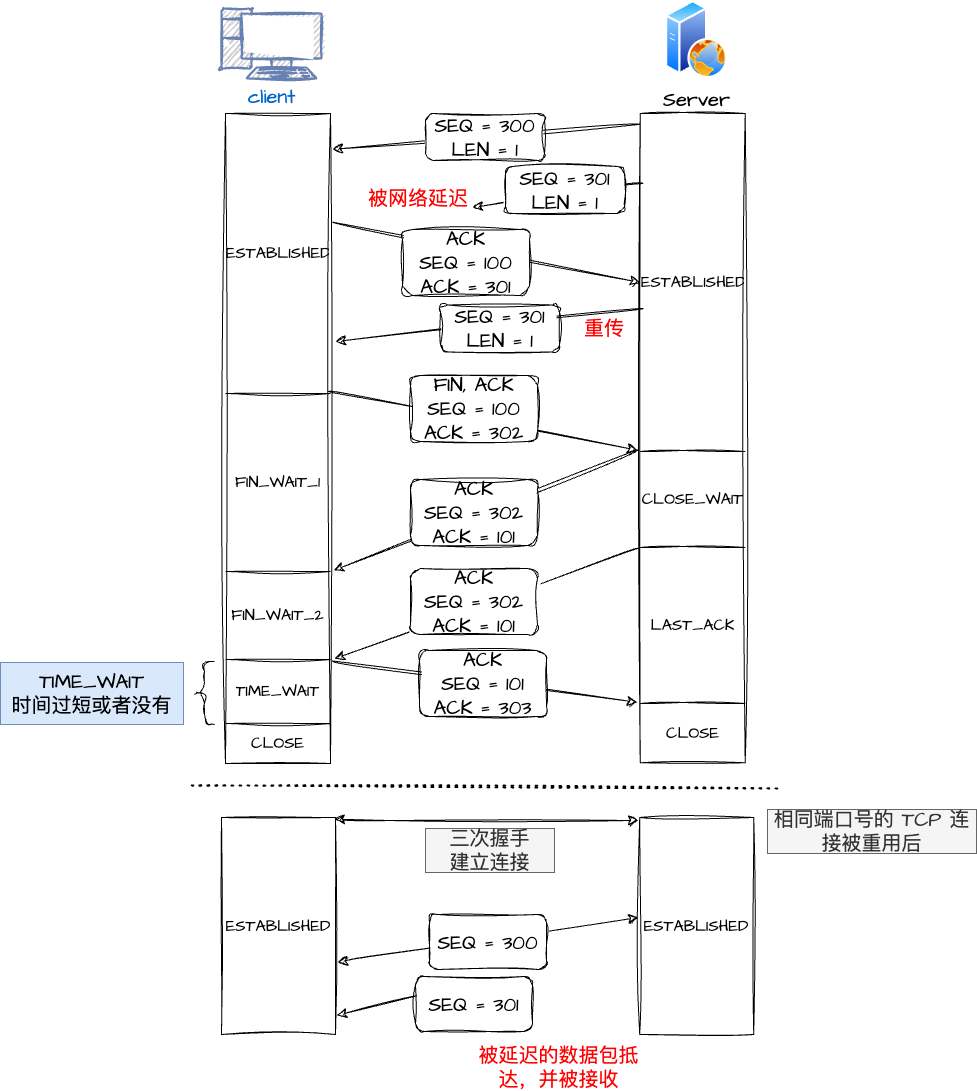
- 服务端在关闭连接之前发送的
SEQ = 301报文,被网络延迟了; - 接着,服务端以相同的四元组重新打开了新连接,前面被延迟的
SEQ = 301这时抵达了客户端,而且该数据报文的序列号刚好在客户端接收窗口内,因此客户端会正常接收这个数据报文,但是这个数据报文是上一个连接残留下来的,这样就产生数据错乱等严重的问题。
为了防止历史连接中的数据被后面相同四元组的连接错误的接收,TCP 设计了
TIME_WAIT 状态,状态会持续 2MSL
时长,这个时间足以让两个方向上的数据包都被丢弃,使得原来连接的数据包在网络中都自然消失,再出现的数据包一定都是新建立连接所产生的。
原因二:保证「被动关闭连接」的一方,能被正确的关闭
如果客户端(主动关闭方)最后一次 ACK 报文(第四次挥手)在网络中丢失了,那么按照 TCP 可靠性原则,服务端(被动关闭方)会重发 FIN 报文。
假设客户端没有 TIME_WAIT 状态,而是在发完最后一次回 ACK 报文就直接进入 CLOSE 状态,如果该 ACK 报文丢失了,服务端则重传的 FIN 报文,而这时客户端已经进入到关闭状态了,在收到服务端重传的 FIN 报文后,就会回 RST 报文。服务端收到这个 RST 并将其解释为一个错误(Connection reset by peer),这对于一个可靠的协议来说不是一个优雅的终止方式。
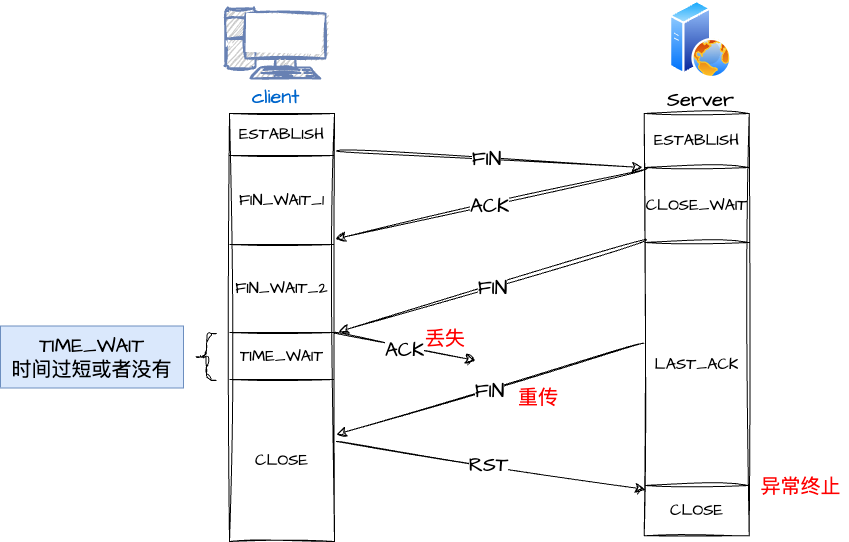
为了防止这种情况出现,客户端必须等待足够长的时间,确保服务端能够收到 ACK,如果服务端没有收到 ACK,那么就会触发 TCP 重传机制,服务端会重新发送一个 FIN,这样一去一来刚好两个 MSL 的时间。客户端在收到服务端重传的 FIN 报文时,TIME_WAIT 状态的等待时间,会重置回 2MSL。
TIME_WAIT 过多有什么危害?
过多的 TIME_WAIT 状态的危害主要有两种:
- 占用系统资源,比如 文件描述符、内存资源、CPU 资源、线程资源等;
- 占用端口资源,端口资源也是有限的,一般可以开启的端口为
32768~61000,也可以通过net.ipv4.ip_local_port_range参数指定范围。
客户端和服务端 TIME_WAIT 过多,造成的影响是不同的。
客户端 WAIT_TIME 过多
如果客户端(主动发起关闭连接方)的 TIME_WAIT 状态过多,占满了所有端口资源,那么就无法对「目的 IP+ 目的 PORT」都一样的服务端发起连接了,但是被使用的端口,还是可以继续对另外一个服务端发起连接的。
因此,客户端(发起连接方)都是和「目的 IP+ 目的 PORT 」都一样的服务端建立连接的话,当客户端的 TIME_WAIT 状态连接过多的话,就会受端口资源限制,如果占满了所有端口资源,那么就无法再跟「目的 IP+ 目的 PORT」都一样的服务端建立连接了。
即使是在这种场景下,只要连接的是不同的服务端,端口是可以重复使用的,所以客户端还是可以向其他服务端发起连接的,这是因为内核在定位一个连接的时候,是通过四元组(源IP、源端口、目的IP、目的端口)信息来定位的,并不会因为客户端的端口一样,而导致连接冲突。
服务端 WAIT_TIME 过多
如果服务端(主动发起关闭连接方)的 TIME_WAIT 状态过多,并不会导致端口资源受限,因为服务端只监听一个端口,而且由于一个四元组唯一确定一个 TCP 连接,因此理论上服务端可以建立很多连接,但是 TCP 连接过多,会占用系统资源,比如文件描述符、内存资源、CPU 资源、线程资源等。
如何优化 TIME_WAIT?
- 调整 TCP 参数:可以通过调整操作系统的 TCP 参数来减少 TIME_WAIT
的持续时间。具体来说,可以修改
net.ipv4.tcp_fin_timeout参数,该参数定义了在连接关闭后,处于 TIME_WAIT 状态的持续时间。减少这个时间可以减少 TIME_WAIT 状态的数量。但要注意,过小的值可能会导致连接关闭通知未能完全传播到网络中的情况。 - 重用连接:在应用程序中,可以尝试使用连接重用来减少连接的频繁建立和关闭,从而减少 TIME_WAIT 状态的产生。例如,在 HTTP 中,可以使用 Keep-Alive 机制来复用连接。
- 使用连接池:对于需要频繁进行 TCP 连接的应用,可以考虑使用连接池技术,将已经建立的连接缓存起来,避免频繁地创建和销毁连接。
- 考虑应用程序设计:在应用程序设计时,可以尽量减少频繁地创建和关闭连接,尽可能地复用已有的连接,从而减少 TIME_WAIT 状态的产生。
注意:虽然可以通过调整参数和优化应用程序来减少 TIME_WAIT 状态的数量,但 TIME_WAIT 状态本身是 TCP 协议的一部分,是为了确保数据传输的可靠性而设计的,过度减少 TIME_WAIT 时间可能会影响数据的完整性和可靠性。
《UNIX网络编程》一书中却说道:TIME_WAIT 是我们的朋友,它是有助于我们的,不要试图避免这个状态,而是应该弄清楚它。
如果服务端要避免过多的 TIME_WAIT 状态的连接,就永远不要主动断开连接,让客户端去断开,由分布在各处的客户端去承受 TIME_WAIT。
服务器出现大量 TIME_WAIT 状态的原因有哪些?
首先需要明确的就是 TIME_WAIT 状态是主动关闭连接方才会出现的状态,所以如果服务器出现大量的 TIME_WAIT 状态的 TCP 连接,就是说明服务器主动断开了很多 TCP 连接。
什么场景下服务器会主动断开连接呢?
- 场景一:HTTP 没有使用长连接
- 场景二:HTTP 长连接超时
- 场景三:HTTP 长连接的请求数量达到上限
场景一:HTTP 没有使用长连接
在 HTTP/1.0 中默认是关闭的,如果浏览器要开启
Keep-Alive,它必须在请求的 header 中添加
Connection: Keep-Alive;然后当服务器收到请求,作出回应的时候,Connection: Keep-Alive也被添加到响应中
header 里。如此这般,TCP
连接就不会中断,而是保持连接。当客户端发送另一个请求时,它会使用同一个
TCP 连接。这一直继续到客户端或服务器端提出断开连接。
从 HTTP/1.1 开始, 就默认是开启了 Keep-Alive,现在大多数浏览器都默认是使用 HTTP/1.1,所以 Keep-Alive 都是默认打开的。一旦客户端和服务端达成协议,那么长连接就建立好了。
如果要关闭 HTTP Keep-Alive,需要在 HTTP 请求或者响应的 header 里添加
Connection:close
信息,也就是说,只要客户端和服务端任意一方的 HTTP header 中有
Connection:close 信息,那么就无法使用 HTTP
长连接的机制。
关闭 HTTP 长连接机制后,每次请求都要经历这样的过程:
graph LR;
A[客户端] -->|发起HTTP请求| B[服务器];
B -->|处理请求| C[返回HTTP响应];
C -->|释放连接| B;
那么此方式就是 HTTP 短连接。
只要任意一方的 HTTP header 中有
Connection:close信息,就无法使用 HTTP 长连接机制,这样在完成一次 HTTP 请求/处理后,就会关闭连接。问题:这时候是客户端还是服务端主动关闭连接呢?
在 RFC 文档中,并没有明确由谁来关闭连接,请求和响应的双方都可以主动关闭 TCP 连接。不过,根据大多数 Web 服务的实现,不管哪一方禁用了 HTTP Keep-Alive,都是由服务端主动关闭连接,那么此时服务端上就会出现 TIME_WAIT 状态的连接。
1)客户端禁用了 HTTP Keep-Alive,服务端开启 HTTP Keep-Alive
当客户端禁用了 HTTP Keep-Alive,这时候 HTTP 请求的 header 就会有
Connection:close 信息,这时服务端在发完 HTTP
响应后,就会主动关闭连接。
这么设计的原因是因为HTTP
是请求-响应模型,发起方一直是客户端,HTTP Keep-Alive
的初衷是为客户端后续的请求重用连接,如果在某次
HTTP 请求-响应模型中,请求的 header 定义了
connection:close
信息,那不再重用这个连接的时机就只有在服务端了,所以在 HTTP
请求-响应这个周期的「末端」关闭连接是合理的。
2)客户端开启了 HTTP Keep-Alive,服务端禁用了 HTTP Keep-Alive
当客户端开启了 HTTP Keep-Alive,而服务端禁用了 HTTP Keep-Alive,这时服务端在发完 HTTP 响应后,服务端也会主动关闭连接。
这么设计的原因是因为在服务端主动关闭连接的情况下,只要调用一次
close() 就可以释放连接,剩下的工作由内核 TCP
栈直接进行了处理,整个过程只有一次
syscall;如果是要求客户端关闭,则服务端在写完最后一个 response
之后需要把这个 socket 放入 readable 队列,调用 select / epoll
去等待事件;然后调用一次 read()
才能知道连接已经被关闭,这其中是两次
syscall,多一次用户态程序被激活执行,而且 socket
保持时间也会更长。
因此,当服务端出现大量的 TIME_WAIT 状态连接的时候,可以排查下是否客户端和服务端都开启了 HTTP Keep-Alive,因为任意一方没有开启 HTTP Keep-Alive,都会导致服务端在处理完一个 HTTP 请求后,就主动关闭连接,此时服务端上就会出现大量的 TIME_WAIT 状态的连接。针对这个场景下,解决的方式也很简单,让客户端和服务端都开启 HTTP Keep-Alive 机制。
场景二:HTTP 长连接超时
HTTP 长连接的特点是,只要任意一端没有明确提出断开连接,则保持 TCP 连接状态。HTTP 长连接可以在同一个 TCP 连接上接收和发送多个 HTTP 请求/应答,避免了连接建立和释放的开销。
如果使用了 HTTP 长连接,如果客户端完成一个 HTTP 请求后,就不再发起新的请求,此时这个 TCP 连接一直占用着不是挺浪费资源的吗?
为了避免资源浪费的情况,web 服务软件一般都会提供一个参数,用来指定
HTTP 长连接的超时时间,比如 Nginx 提供的 keepalive_timeout
参数。
假设设置了 HTTP 长连接的超时时间是 60 秒,Nginx 就会启动一个「定时器」,如果客户端在完后一个 HTTP 请求后,在 60 秒内都没有再发起新的请求,定时器的时间一到,Nginx 就会触发回调函数来关闭该连接,那么此时服务端上就会出现 TIME_WAIT 状态的连接。
当服务端出现大量 TIME_WAIT 状态的连接时,如果现象是有大量的客户端建立完 TCP 连接后,很长一段时间没有发送数据,那么大概率就是因为 HTTP 长连接超时,导致服务端主动关闭连接,产生大量处于 TIME_WAIT 状态的连接。
解决方案是可以往网络问题的方向排查,比如是否是因为网络问题,导致客户端发送的数据一直没有被服务端接收到,以至于 HTTP 长连接超时。
场景三:HTTP 长连接的请求数量达到上限
Web 服务端通常会有个参数,来定义一条 HTTP 长连接上最大能处理的请求数量,当超过最大限制时,就会主动关闭连接。
比如 Nginx 的 keepalive_requests
这个参数,这个参数是指一个 HTTP 长连接建立之后,Nginx
就会为这个连接设置一个计数器,记录这个 HTTP
长连接上已经接收并处理的客户端请求的数量。如果达到这个参数设置的最大值时,则
Nginx 会主动关闭这个长连接,那么此时服务端上就会出现 TIME_WAIT
状态的连接。keepalive_requests 参数的默认值是 100
,意味着每个 HTTP 长连接最多只能跑 100 次请求,在一些 QPS (每秒请求数)
不是很高的场合,默认值 100 凑合够用。
但是,对于一些 QPS 比较高的场景,比如超过 10000 QPS,甚至达到 30000 , 50000 甚至更高,如果 keepalive_requests 参数值是 100,这时候就 Nginx 就会很频繁地关闭连接,那么此时服务端上就会出大量的 TIME_WAIT 状态。
针对这个场景下,解决的方式也很简单,调大 Nginx 的
keepalive_requests 参数就行。