《MySQL是怎样运行的 —— 从跟上理解MySQL》—— 第九章
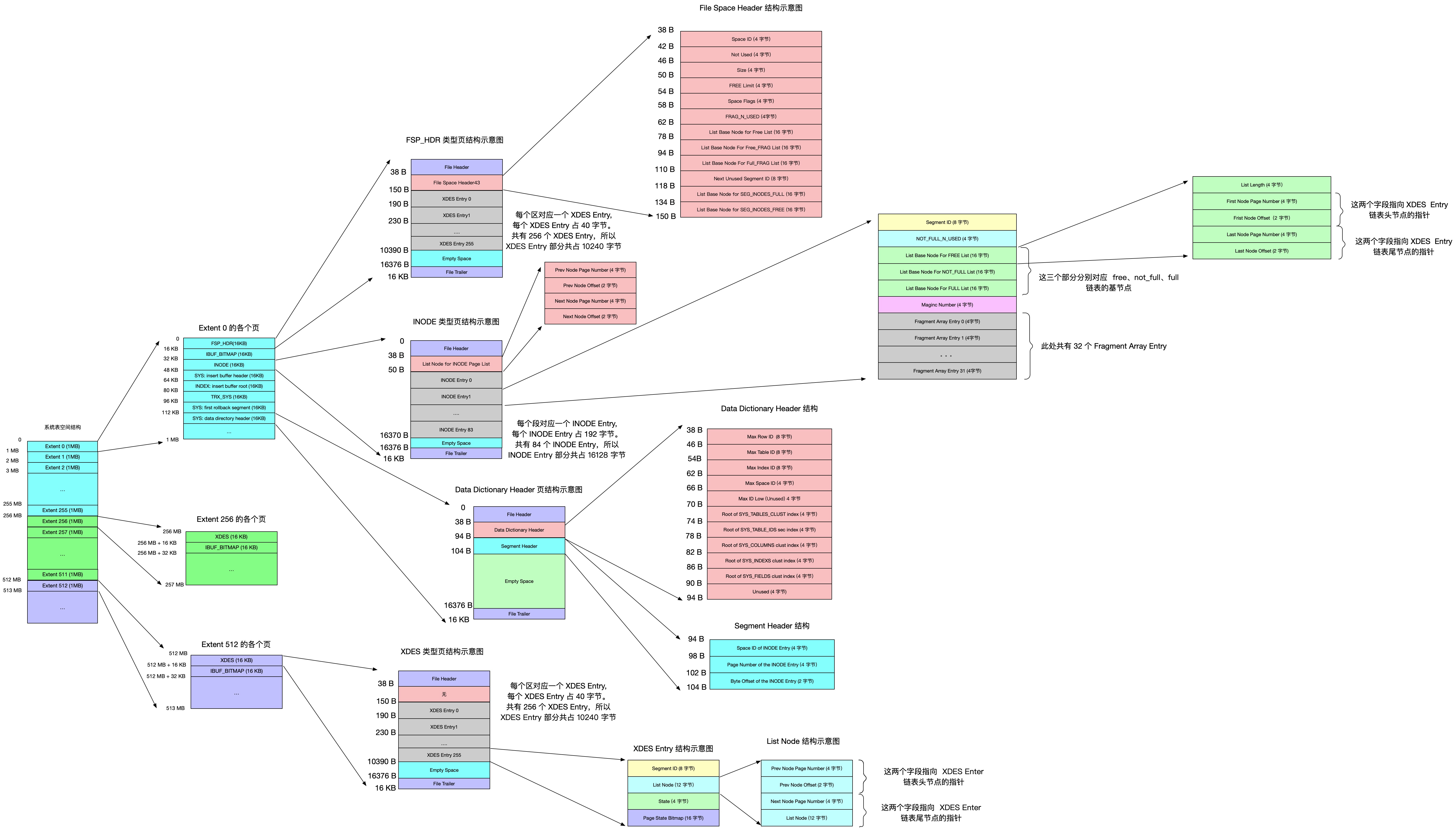
表空间是一个抽象的概念,对于系统表空间来说,对应着文件系统中一个或多个实际文件;对于每个独立表空间来说,对应着文件系统中一个名为表名.ibd的实际文件。
可以把表空间理解成被切分为许许多多个页的池子,当想为某个表插入一条记录的时候,就从池子中捞出一个对应的页来把数据写进去。
一、回顾
1.1 页类型
InnoDB是以页为单位管理存储空间的,聚簇索引(也就是完整的表数据)和其他的二级索引都是以B+树的形式保存到表空间的,而B+树的节点就是数据页,这个数据页的类型名是FIL_PAGE_INDEX,除了这种存放索引数据的页类型之外,InnoDB也为了不同的目的设计了若干种不同类型的页。常用的页类型:
| 类型名称 | 十六进制 | 描述 |
|---|---|---|
FIL_PAGE_TYPE_ALLOCATED |
0x0000 | 最新分配,还没使用 |
FIL_PAGE_UNDO_LOG |
0x0002 | Undo日志页 |
FIL_PAGE_INODE |
0x0003 | 段信息节点 |
FIL_PAGE_IBUF_FREE_LIST |
0x0004 | Insert Buffer空闲列表 |
FIL_PAGE_IBUF_BITMAP |
0x0005 | Insert Buffer位图 |
FIL_PAGE_TYPE_SYS |
0x0006 | 系统页 |
FIL_PAGE_TYPE_TRX_SYS |
0x0007 | 事务系统数据 |
FIL_PAGE_TYPE_FSP_HDR |
0x0008 | 表空间头部信息 |
FIL_PAGE_TYPE_XDES |
0x0009 | 扩展描述页 |
FIL_PAGE_TYPE_BLOB |
0x000A | BLOB页 |
FIL_PAGE_INDEX |
0x45BF | 索引页,也就是我们所说的数据页 |
因为页类型前面都有个FIL_PAGE或者FIL_PAGE_TYPE的前缀,为简便起见后面描述页类型的时候就把这些前缀省略掉了,比方说FIL_PAGE_TYPE_ALLOCATED类型称为ALLOCATED类型,FIL_PAGE_INDEX类型称为INDEX类型。
1.2 页面通用部分
INDEX类型的页由7个部分组成,其中的两个部分是所有类型的页都通用的。
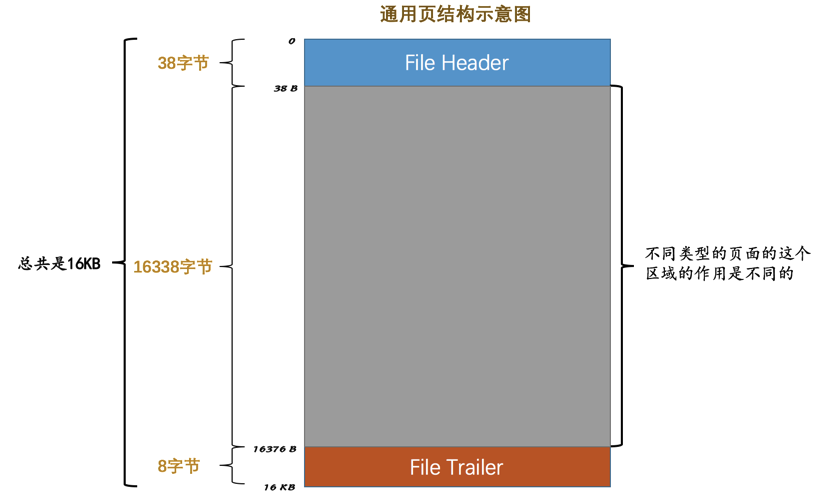
任何类型的页都会包含这两个部分:
File Header:记录页的一些通用信息File Trailer:校验页是否完整,保证从内存到磁盘刷新时内容的一致性。
File Header的各个组成部分:
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
FIL_PAGE_SPACE_OR_CHKSUM |
4字节 |
页的校验和(checksum值) |
FIL_PAGE_OFFSET |
4字节 |
页号 |
FIL_PAGE_PREV |
4字节 |
上一个页的页号 |
FIL_PAGE_NEXT |
4字节 |
下一个页的页号 |
FIL_PAGE_LSN |
8字节 |
页被最后修改时对应的日志序列位置(Log Sequence Number) |
FIL_PAGE_TYPE |
2字节 |
该页的类型 |
FIL_PAGE_FILE_FLUSH_LSN |
8字节 |
仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的LSN值 |
FIL_PAGE_ARCH_LOG_NO_OR_SPACE_ID |
4字节 |
页属于哪个表空间 |
- 表空间中的每一个页都对应着一个页号(
FIL_PAGE_OFFSET),这个页号由4个字节组成,32个比特位,所以一个表空间最多可以拥有232个页,如果按照页的默认大小16KB来算,一个表空间最多支持64TB的数据。表空间的第一个页的页号为0,之后的页号分别是1,2,3...依此类推 - 某些类型的页可以组成链表,链表中的页可以不按照物理顺序存储,而是根据
FIL_PAGE_PREV和FIL_PAGE_NEXT来存储上一个页和下一个页的页号。需要注意的是,这两个字段主要是为了INDEX类型的页,即数据页建立B+树后,为每层节点建立双向链表用的,一般类型的页是不使用这两个字段。 - 每个页的类型由
FIL_PAGE_TYPE表示,比如数据页的该字段的值就是0x45BF。
二、独立表空间结构
2.1 区 (extent) 的概念
由于表空间中的页太多,为了更好的管理这些页,InnoDB的使用了区(extent)的概念。对于16KB的页来说,连续的64个页就是一个区,即一个区默认占用1MB空间大小。不论是系统表空间还是独立表空间,都可以看成是由若干个区组成的,每256个区被划分成一组。
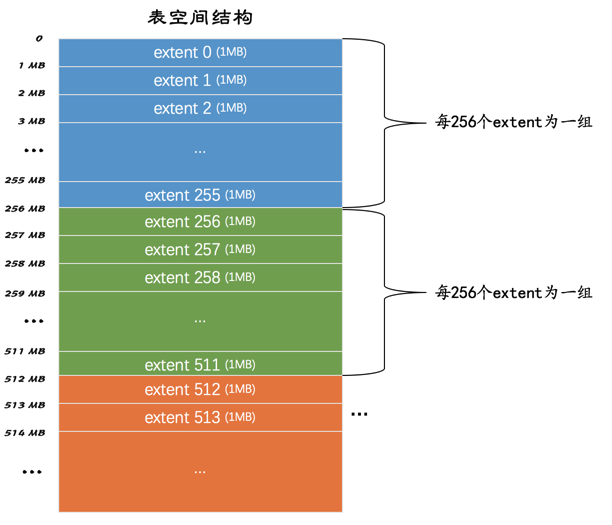
其中extent 0 ~
extent 255这256个区算是第一个组,extent 256 ~
extent 511这256个区算是第二个组,extent 512 ~
extent 767这256个区算是第三个组,依此类推可以划分更多的组。这些组的头几个页的类型都是类似的:
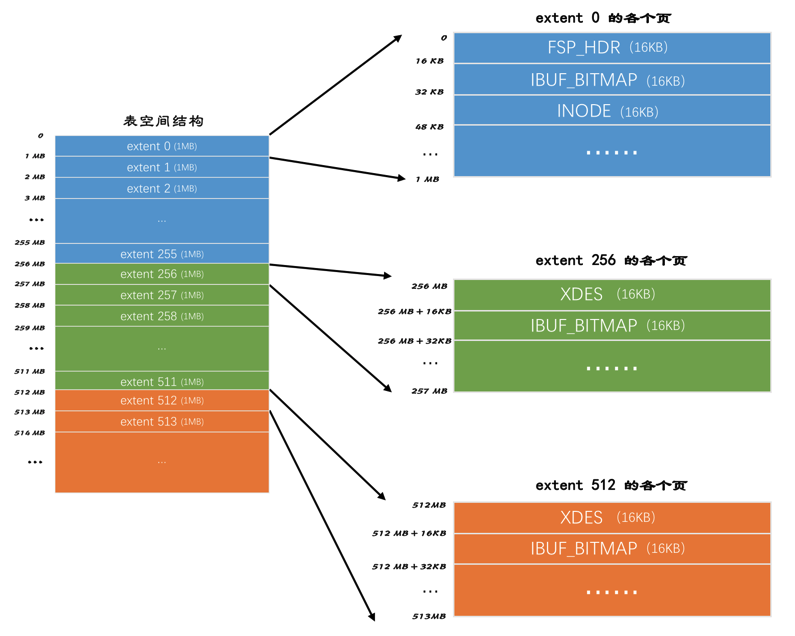
可以发现:
- 第一个组最开始的3个页的类型是固定的,即
extent 0这个区最开始的3个页的类型是固定的,分别是:FSP_HDR类型:这个类型的页是用来登记整个表空间的一些整体属性以及本组所有的区,也就是extent 0~extent 255这256个区的属性。需要注意的一点是,整个表空间只有一个FSP_HDR类型的页。IBUF_BITMAP类型:这个类型的页是存储本组所有的区的所有页关于CHANGE BUFFER的信息。INODE类型:这个类型的页存储了许多INODE的数据结构。
- 其余各组最开始的2个页的类型是固定的,也就是说
extent 256、extent 512这些区最开始的2个页的类型是固定的,分别是:XDES类型:全称是extent descriptor,用来登记本组256个区的属性,也就是说对于在extent 256区中的该类型页存储的就是extent 256~extent 511这些区的属性,对于在extent 512区中的该类型页存储的就是extent 512~extent 767这些区的属性。FSP_HDR类型的页其实和XDES类型的页(扩展描述页)的作用类似,只不过FSP_HDR类型的页还会额外存储一些表空间的属性。IBUF_BITMAP类型:同上。
重点:表空间被划分为许多连续的区,每个区默认由64个页组成,每256个区划分为一组,每个组的最开始的几个页类型是固定的。
2.2 段 (Segment)
之前分析问题的套路:表中的记录存储到页里边儿,然后页作为节点组成B+树,这个B+树就是索引,其次就是聚簇索引和二级索引的区别……这好像不需要用到区(extent)的概念。
如果表中数据量很少的话,比如表中只有几十条、几百条数据的话,的确用不到区的概念,因为简单的几个页就能把对应的数据存储起来,但是终究架不住表里的记录越来越多呀。
问题:表里的记录多了又怎样?B+树的每一层中的页都会形成一个双向链表呀,File Header中的FIL_PAGE_PREV和FIL_PAGE_NEXT字段不就是为了形成双向链表设置的么?
从理论上说,不引入区的概念只使用页的概念对存储引擎的运行并没什么影响,但是需要考虑一种场景:
向表中插入一条记录,本质上就是向该表的聚簇索引以及所有二级索引代表的B+树的节点中插入数据。而B+树的每一层中的页都会形成一个双向链表,如果是以页为单位来分配存储空间的话,双向链表相邻的两个页之间的物理位置可能离得非常远。B+树索引的适用场景中就有范围查询,即只需要定位到最左边的记录和最右边的记录,然后沿着双向链表一直扫描就可以了,而如果链表中相邻的两个页物理位置离得非常远,就是所谓的随机I/O。而磁盘的速度和内存的速度差了好几个数量级,随机I/O是非常慢的,所以应该尽量让链表中相邻的页的物理位置也相邻,这样进行范围查询的时候才可以使用所谓的顺序I/O。
所以才引入了区(extent)的概念,一个区就是在物理位置上连续的64个页。在表中数据量大的时候,为某个索引分配空间的时候就不再按照页为单位分配了,而是按照区为单位分配,甚至在表中的数据十分非常特别多的时候,可以一次性分配多个连续的区。虽然可能造成一点点空间的浪费(数据不足填充满整个区),但是从性能角度看,可以消除很多的随机I/O。
除此之外,还需要注意在上述提及的范围查询中,其实是对B+树叶子节点中的记录进行顺序扫描,而如果不区分叶子节点和非叶子节点,统统把节点代表的页放到申请到的区中的话,进行范围扫描的效果就大打折扣了。
因此InnoDB对B+树的叶子节点和非叶子节点进行了区分,也就是说叶子节点有自己独有的区,非叶子节点也有自己独有的区。存放叶子节点的区的集合就算是一个段(segment),存放非叶子节点的区的集合也算是一个段。也就是说一个索引会生成2个段,一个叶子节点段,一个非叶子节点段。
问题:默认情况下一个使用InnoDB存储引擎的表只有一个聚簇索引,一个索引会生成2个段,而段是以区为单位申请存储空间的,一个区默认占用1M存储空间,所以默认情况下一个只存了几条记录的小表也需要2M的存储空间么?以后每次添加一个索引都要多申请2M的存储空间么?这对于存储记录比较少的表是很浪费的。
这个问题的根源在于到现在为止的区都是非常纯粹的,也就是一个区被整个分配给某一个段,或者说区中的所有页都是为了存储同一个段的数据而存在的,即使段的数据填不满区中所有的页,那余下的页也不能挪作他用。现在为了考虑以完整的区为单位分配给某个段对于数据量较小的表太浪费存储空间的这种情况,InnoDB使用了碎片(fragment)区的概念,也就是在一个碎片区中,并不是所有的页都是为了存储同一个段的数据而存在的,而是碎片区中的页可以用于不同的目的,比如有些页用于段A,有些页用于段B,有些页甚至哪个段都不属于。碎片区直属于表空间,并不属于任何一个段。所以此后为某个段分配存储空间的策略是这样的:
- 在刚开始向表中插入数据的时候,段是从某个碎片区以单个页为单位来分配存储空间的。
- 当某个段已经占用了32个碎片区页之后,就会以完整的区为单位来分配存储空间。
此时,段更精确的定义应该是某些零散的页以及一些完整的区的集合。除了索引的叶子节点段和非叶子节点段之外,InnoDB中还有为存储一些特殊的数据而定义的段,比如回滚段,
2.3 区的分类
表空间的是由若干个区组成的,这些区大体上可以分为4种类型:
- 空闲的区:现在还没有用到这个区中的任何页。
- 有剩余空间的碎片区:表示碎片区中还有可用的页。
- 没有剩余空间的碎片区:表示碎片区中的所有页都被使用,没有空闲页。
- 附属于某个段的区。每一个索引都可以分为叶子节点段和非叶子节点段,除此之外InnoDB还会另外定义一些特殊作用的段,在这些段中的数据量很大时将使用区来作为基本的分配单位。
这4种类型的区也可以被称为区的4种状态(State):
| 状态名 | 含义 |
|---|---|
FREE |
空闲的区 |
FREE_FRAG |
有剩余空间的碎片区 |
FULL_FRAG |
没有剩余空间的碎片区 |
FSEG |
附属于某个段的区 |
⚠️注意:处于FREE、FREE_FRAG以及FULL_FRAG这三种状态的区都是独立的,算是直属于表空间;而处于FSEG状态的区是附属于某个段的。
为了方便管理这些区,InnoDB使用了XDES Entry的结构(Extent
Descriptor
Entry),每一个区都对应着一个XDES Entry结构,这个结构记录了对应的区的一些属性。

可以看到,XDES Entry是一个40个字节的结构,大致分为4个部分:
Segment ID(8字节):每一个段都有一个唯一的编号,用ID表示,此处的Segment ID字段表示就是该区所在的段。(前提是该区已经被分配给某个段了,不然的话该字段的值没有意义。)List Node(12字节):这个部分可以将若干个XDES Entry结构串联成一个链表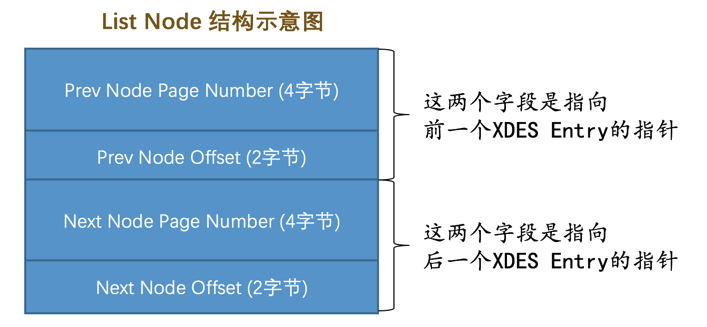
如果想定位表空间内的某一个位置的话,只需指定页号以及该位置在指定页号中的页内偏移量即可。所以:
Pre Node Page Number和Pre Node Offset的组合就是指向前一个XDES Entry的指针。Next Node Page Number和Next Node Offset的组合就是指向后一个XDES Entry的指针。
State(4字节):这个字段表明区的状态。可选的值就是前面的那4个,分别是:FREE、FREE_FRAG、FULL_FRAG和FSEG。Page State Bitmap(16字节):这个部分共占用16个字节,也就是128个比特位。我们说一个区默认有64个页,这128个比特位被划分为64个部分,每个部分2个比特位,对应区中的一个页。比如Page State Bitmap部分的第1和第2个比特位对应着区中的第1个页,第3和第4个比特位对应着区中的第2个页,依此类推,Page State Bitmap部分的第127和128个比特位对应着区中的第64个页。这两个比特位的第一个位表示对应的页是否是空闲的,第二个比特位还没有用。
2.3.1 XDES Entry链表
上述提出了一堆区、段、碎片区、附属于段的区、
XDES Entry结构等等的概念,本质上是想提高向表插入数据的效率,又不至于数据量少的表浪费空间。
梳理向某个段中插入数据时,申请新页面的过程:
当段中数据较少的时候,首先会查看表空间中是否有状态为FREE_FRAG的区,也就是找还有空闲空间的碎片区,如果找到了,那么从该区中取一些零碎的页把数据插进去;否则到表空间下申请一个状态为FREE的区,也就是空闲的区,把该区的状态变为FREE_FRAG,然后从该新申请的区中取一些零碎的页把数据插进去。之后不同的段使用零碎页的时候都会从该区中取,直到该区中没有空闲空间,然后该区的状态就变成了FULL_FRAG。
问题:怎么知道表空间里的哪些区是FREE的,哪些区的状态是FREE_FRAG的,哪些区是FULL_FRAG的?表空间的大小是可以不断增大的,当增长到GB级别的时候,区的数量也就上千了,总不能每次都遍历这些区对应的XDES Entry结构吧?
此时XDES Entry中的List Node部分发挥作用的时候了。
可以通过List Node中的指针操作三个链表:
- 把状态为
FREE的区对应的XDES Entry结构通过List Node来连接成一个链表,这个链表称之为FREE链表。 - 把状态为
FREE_FRAG的区对应的XDES Entry结构通过List Node来连接成一个链表,这个链表称之为FREE_FRAG链表。 - 把状态为
FULL_FRAG的区对应的XDES Entry结构通过List Node来连接成一个链表,这个链表称之为FULL_FRAG链表。
这样每当想找一个FREE_FRAG状态的区时,就直接把FREE_FRAG链表的头节点拿出来,从这个节点中取一些零碎的页来插入数据,当这个节点对应的区用完时,就修改一下这个节点的State字段的值,然后从FREE_FRAG链表中移到FULL_FRAG链表中。同理,如果FREE_FRAG链表中一个节点都没有,那么就直接从FREE链表中取一个节点移动到FREE_FRAG链表的状态,并修改该节点的STATE字段值为FREE_FRAG,然后从这个节点对应的区中获取零碎的页就好了。
当段中数据已经占满了32个零散的页后,就直接申请完整的区来插入数据了。
问题:怎么知道哪些区属于哪个段的呢?
InnoDB为每个段中的区对应的XDES Entry结构建立了三个链表:
FREE链表:同一个段中,所有页都是空闲的区对应的XDES Entry结构会被加入到这个链表。注意和直属于表空间的FREE链表区别开了,此处的FREE链表是附属于某个段的。NOT_FULL链表:同一个段中,仍有空闲空间的区对应的XDES Entry结构会被加入到这个链表。FULL链表:同一个段中,已经没有空闲空间的区对应的XDES Entry结构会被加入到这个链表。
⚠️注意:每一个索引都对应两个段,每个段都会维护上述的3个链表。
2.3.2 链表基节点
问题:怎么找到上述说的那么多链表呢?或者说怎么找到某个链表的头节点或者尾节点在表空间中的位置呢?
InnoDB使用了一个叫List Base Node的结构,这个结构中包含了链表的头节点和尾节点的指针以及这个链表中包含了多少节点的信息:

上述的每个链表都对应这么一个List Base Node结构,其中:
List Length表明该链表一共有多少节点,First Node Page Number和First Node Offset表明该链表的头节点在表空间中的位置。Last Node Page Number和Last Node Offset表明该链表的尾节点在表空间中的位置。
一般把某个链表对应的List Base Node结构放置在表空间中固定的位置,这样想找定位某个链表就很简单了。
2.3.3 链表小结
综上所述,表空间是由若干个区组成的,每个区都对应一个XDES Entry的结构,直属于表空间的区对应的XDES Entry结构可以分成FREE、FREE_FRAG和FULL_FRAG这3个链表;每个段可以附属若干个区,每个段中的区对应的XDES Entry结构可以分成FREE、NOT_FULL和FULL这3个链表。每个链表都对应一个List Base Node的结构,这个结构里记录了链表的头、尾节点的位置以及该链表中包含的节点数。正是因为这些链表的存在,管理这些区才变得简单。
2.4 段的结构
段并不对应表空间中某一个连续的物理区域,而是一个逻辑上的概念,由若干个零散的页以及一些完整的区组成。
InnoDB为每个段都定义了一个INODE Entry结构来记录一下段中的属性。

各个部分的含义:
Segment ID:指这个INODE Entry结构对应的段的编号(ID)。NOT_FULL_N_USED:指的是在NOT_FULL链表中已经使用了多少个页。下次从NOT_FULL链表分配空闲页时可以直接根据这个字段的值定位到。而不用从链表中的第一个页开始遍历着寻找空闲页。- 3个
List Base Node:分别为段的FREE链表、NOT_FULL链表、FULL链表定义了List Base Node,这样想查找某个段的某个链表的头节点和尾节点的时候,就可以直接到这个部分找到对应链表的List Base Node。 Magic Number:标记这个INODE Entry是否已经被初始化了(初始化的意思就是把各个字段的值都填进去了)。如果这个数字是值的97,937,874,表明该INODE Entry已经初始化,否则没有被初始化。(不用纠结这个值有什么特殊含义,设计者规定的)。Fragment Array Entry:共4个字节,表示一个零散页的页号(段是一些零散页和一些完整的区的集合,每个Fragment Array Entry结构都对应着一个零散的页)。
2.5 各类型页面的详细情况
2.5.1 FSP_HDR类型
第一个组的第一个页,也是表空间的第一个页,页号为0。这个页的类型是FSP_HDR,它存储了表空间的一些整体属性以及第一个组内256个区的对应的XDES Entry结构,

一个完整的FSP_HDR类型的页大致由5个部分组成:
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
File Header |
文件头部 | 38字节 |
页的一些通用信息 |
File Space Header |
表空间头部 | 112字节 |
表空间的一些整体属性信息 |
XDES Entry |
区描述信息 | 10240字节 |
存储本组256个区对应的属性信息 |
Empty Space |
尚未使用空间 | 5986字节 |
用于页结构的填充,没什么实际意义 |
File Trailer |
文件尾部 | 8字节 |
校验页是否完整 |
1)File Space Header
这个部分是存储表空间的一些整体属性:

| 名称 | 占用空间大小 | 描述 |
|---|---|---|
Space ID |
4字节 |
表空间的ID |
Not Used |
4字节 |
这4个字节未被使用,忽略 |
Size |
4字节 |
当前表空间占有的页数 |
FREE Limit |
4字节 |
尚未被初始化的最小页号,大于或等于这个页号的区对应的XDES Entry结构都没有被加入FREE链表 |
Space Flags |
4字节 |
表空间的一些占用存储空间比较小的属性 |
FRAG_N_USED |
4字节 |
FREE_FRAG链表中已使用的页数量 |
List Base Node for FREE List |
16字节 |
FREE链表的基节点 |
List Base Node for FREE_FRAG List |
16字节 |
FREE_FREG链表的基节点 |
List Base Node for FULL_FRAG List |
16字节 |
FULL_FREG链表的基节点 |
Next Unused Segment ID |
8字节 |
当前表空间中下一个未使用的 Segment ID |
List Base Node for SEG_INODES_FULL List |
16字节 |
SEG_INODES_FULL链表的基节点 |
List Base Node for SEG_INODES_FREE List |
16字节 |
SEG_INODES_FREE链表的基节点 |
List Base Node for FREE List、List Base Node for FREE_FRAG List、List Base Node for FULL_FRAG List:分别是直属于表空间的FREE链表的基节点、FREE_FRAG链表的基节点、FULL_FRAG链表的基节点,这三个链表的基节点在表空间的位置是固定的,就是在表空间的第一个页(也就是FSP_HDR类型的页)的File Space Header部分。所以之后定位这几个链表就很简单了。FRAG_N_USED:这个字段表明在FREE_FRAG链表中已经使用的页数量,方便之后在链表中查找空闲的页。FREE Limit:表空间都对应着具体的磁盘文件,一开始创建表空间的时候对应的磁盘文件中都没有数据,所以需要对表空间完成一个初始化操作,包括为表空间中的区建立XDES Entry结构,为各个段建立INODE Entry结构,建立各种链表等等的各种操作。可以一开始就为表空间申请一个特别大的空间,但是实际上有绝大部分的区是空闲的,可以选择把所有的这些空闲区对应的
XDES Entry结构加入FREE链表,也可以选择只把一部分的空闲区加入FREE链表,等什么时候空闲链表中的XDES Entry结构对应的区不够使了,再把之前没有加入FREE链表的空闲区对应的XDES Entry结构加入FREE链表,中心思想就是什么时候用到什么时候初始化,InnoDB采用的是后者,它为表空间定义了FREE Limit这个字段,在该字段表示的页号之前的区都被初始化了,之后的区尚未被初始化。Next Unused Segment ID:表中每个索引都对应2个段,每个段都有一个唯一的ID,那当为某个表新创建一个索引的时候,就意味着要创建两个新的段。那为这个新创建的段找一个唯一的ID就需要使用到这个名叫Next Unused Segment ID的字段,该字段表明当前表空间中最大的段ID的下一个ID,这样在创建新段的时候赋予新段一个唯一的ID值直接使用这个字段的值即可。Space Flags:表空间对于一些布尔类型的属性,或者只需要寥寥几个比特位搞定的属性都放在了这个Space Flags中存储(针对MySQL 5.7.21)标志名称 占用的空间(bit) 描述 POST_ANTELOPE1 表示文件格式是否大于 ANTELOPEZIP_SSIZE4 表示压缩页的大小 ATOMIC_BLOBS1 表示是否自动把值非常长的字段放到BLOB页里 PAGE_SSIZE4 页大小 DATA_DIR1 表示表空间是否是从默认的数据目录中获取的 SHARED1 是否为共享表空间 TEMPORARY1 是否为临时表空间 ENCRYPTION1 表空间是否加密 UNUSED18 没有使用到的比特位 List Base Node for SEG_INODES_FULL List和List Base Node for SEG_INODES_FREE List:每个段对应的INODE Entry结构会集中存放到一个类型位INODE的页中,如果表空间中的段特别多,则会有多个INODE Entry结构,可能一个页放不下,这些INODE类型的页会组成两种列表:SEG_INODES_FULL链表,该链表中的INODE类型的页都已经被INODE Entry结构填充满了,没空闲空间存放额外的INODE Entry了。SEG_INODES_FREE链表,该链表中的INODE类型的页都已经仍有空闲空间来存放INODE Entry结构。
2)XDES Entry
紧接着File Space Header部分的就是XDES Entry部分了。XDES Entry是在表空间的第一个页中保存的。一个XDES Entry结构的大小是40字节,但是一个页的大小有限,只能存放有限个XDES Entry结构,所以才把256个区划分成一组,在每组的第一个页中存放256个XDES Entry结构。回顾FSP_HDR类型页的示意图,XDES Entry 0就对应着extent 0,XDES Entry 1就对应着extent 1...
依此类推,XDES Entry255就对应着extent 255。
因为每个区对应的XDES Entry结构的地址是固定的,所以访问这些结构就很简单了,计算对应的偏移量即可。
2.5.2 XDES类型
每一个XDES Entry结构对应表空间的一个区,虽然一个XDES Entry结构只占用40字节,但是也架不住表空间的区的数量也多啊。在区的数量非常多时,一个单独的页可能就不够存放足够多的XDES Entry结构,因此把表空间的区分为了若干个组,每组开头的一个页记录着本组内所有的区对应的XDES Entry结构。由于第一个组的第一个页有些特殊,因为它也是整个表空间的第一个页,所以除了记录本组中的所有区对应的XDES Entry结构以外,还记录着表空间的一些整体属性,这个页的类型就是FSP_HDR类型,整个表空间里只有一个这个类型的页。除去第一个分组以外,之后的每个分组的第一个页只需要记录本组内所有的区对应的XDES Entry结构即可,不需要再记录表空间的属性了,为了和FSP_HDR类型做区别,将之后每个分组的第一个页的类型定义为XDES:
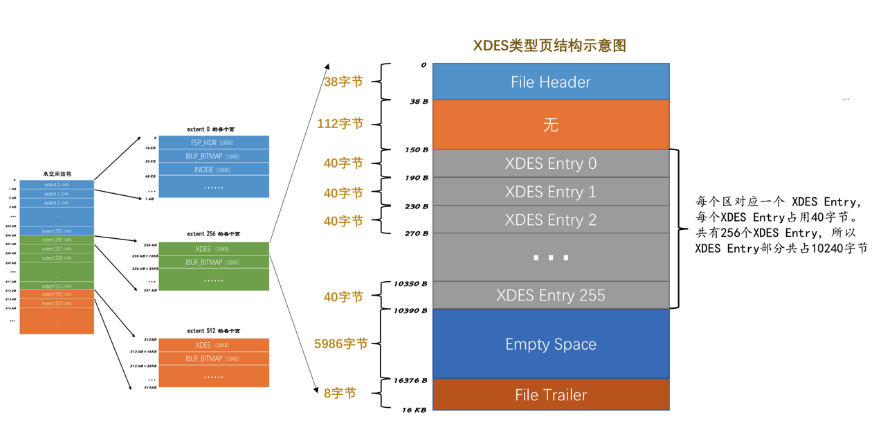
它的结构和FSP_HDR类型非常相似,与FSP_HDR类型的页对比,除了少了File Space Header部分之外,也就是除了少了记录表空间整体属性的部分之外,其余的部分是一样一样的。
2.5.3 IBUF_BITMAP类型
每个分组的第二个页的类型都是IBUF_BITMAP,这种类型的页里边记录了一些有关Change Buffer的信息。
向表中插入一条记录, 其实本质上是向每个索引对应的
B+树中插入记录。该记录首先插入聚簇索引页面,然后再插入每个二级索引页面。这些页面在表空间中随机分布,将会产生大量的随机I/O,严重影响性能。对于UPDATE和DELETE操作来说,也会带来许多的随机I/O。所以InnoDB引入了一种称为Change
Buffer的结构(本质上也是表空间中的一颗B+树,它的根节点存储在系统表空间中)。在修改非唯一二
级索引页面时 (修改唯一二级索引页面时是否利用 Change
Buffer取决于很多情况,此处不涉及)
。如果该页面尚未被加载到内存中,即仍在磁盘上,那么该修改将先被暂时缓存到Change
Buffer中,之后服务器空闲或者其他什么原因导致对应的页面从磁盘上加载到内存中时,再将修改合并到对应页面。
此外,在很久之前的版本中只会缓存 INSERT操作对二 级索引页面所做的修改,所以 ChangeBuffer以前被称作Insert Buffer。所以在各种命名上延续了之前的叫法,比方说IBUF其实是Insert Buffer的缩写。
2.5.4 INODE类型
第一个分组的第三个页的类型是INODE。InnoDB为每个索引定义了两个段,而且为某些特殊功能定义了些特殊的段。为了方便管理,InnoDB又为每个段设计了一个INODE Entry结构,这个结构中记录了关于这个段的相关属性。而INODE类型的页就是为了存储INODE Entry结构而存在的。
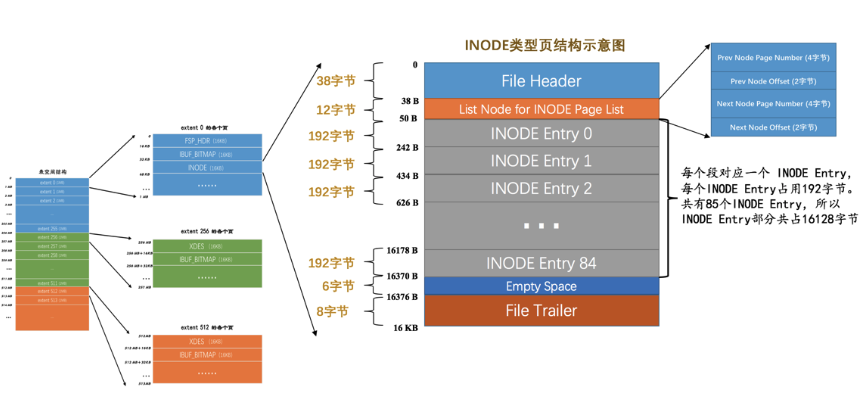
| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
File Header |
文件头部 | 38字节 |
页的一些通用信息 |
List Node for INODE Page List |
通用链表节点 | 12字节 |
存储上一个INODE页和下一个INODE页的指针 |
INODE Entry |
段描述信息 | 16128字节 |
|
Empty Space |
尚未使用空间 | 6字节 |
用于页结构的填充,没什么实际意义 |
File Trailer |
文件尾部 | 8字节 |
校验页是否完整 |
INODE Entry:主要包括对应的段内零散页的地址以及附属于该段的FREE、NOT_FULL和FULL链表的基节点。每个INODE Entry结构占用192字节,一个页里可以存储85个这样的结构。List Node for INODE Page List:因为一个表空间中可能存在超过85个段,所以可能一个INODE类型的页不足以存储所有的段对应的INODE Entry结构,所以就需要额外的INODE类型的页来存储这些结构。为了方便管理这些INODE类型的页,InnoDB将这些INODE类型的页串联成两个不同的链表:SEG_INODES_FULL链表:该链表中的INODE类型的页中已经没有空闲空间来存储额外的INODE Entry结构了。SEG_INODES_FREE链表:该链表中的INODE类型的页中还有空闲空间来存储额外的INODE Entry结构了。
这两个链表的基节点就存储在
File Space Header中,也就是说这两个链表的基节点的位置是固定的,所以我们可以很轻松的访问到这两个链表。
以后每当新创建一个段(创建索引时就会创建段)时,都会创建一个INODE Entry结构与之对应,存储INODE Entry的大致过程就是这样的:
- 先看看
SEG_INODES_FREE链表是否为空,如果不为空,直接从该链表中获取一个节点,也就相当于获取到一个仍有空闲空间的INODE类型的页,然后把该INODE Entry结构防到该页中。当该页中无剩余空间时,就把该页放到SEG_INODES_FULL链表中。 - 如果
SEG_INODES_FREE链表为空,则需要从表空间的FREE_FRAG链表中申请一个页,修改该页的类型为INODE,把该页放到SEG_INODES_FREE链表中,与此同时把该INODE Entry结构放入该页。
2.6 Segment Header结构的运用
问题:一个索引会产生两个段,分别是叶子节点段和非叶子节点段,而每个段都会对应一个INODE Entry结构,那我们怎么知道某个段对应哪个INODE Entry结构呢?
得找个地方存储这个对应关系
Page Header的重点部分:
| 名称 | 占用空间大小 | 描述 |
|---|---|---|
| ... | ... | ... |
PAGE_BTR_SEG_LEAF |
10字节 |
B+树叶子段的头部信息,仅在B+树的根页定义 |
PAGE_BTR_SEG_TOP |
10字节 |
B+树非叶子段的头部信息,仅在B+树的根页定义 |
其中的PAGE_BTR_SEG_LEAF和PAGE_BTR_SEG_TOP都占用10个字节,它们其实对应一个叫Segment Header的结构:

| 名称 | 占用字节数 | 描述 |
|---|---|---|
Space ID of the INODE Entry |
4 |
INODE Entry结构所在的表空间ID |
Page Number of the INODE Entry |
4 |
INODE Entry结构所在的页页号 |
Byte Offset of the INODE Ent |
2 |
INODE Entry结构在该页中的偏移量 |
PAGE_BTR_SEG_LEAF记录着叶子节点段对应的INODE Entry结构的地址是哪个表空间的哪个页的哪个偏移量,PAGE_BTR_SEG_TOP记录着非叶子节点段对应的INODE Entry结构的地址是哪个表空间的哪个页的哪个偏移量。这样子索引和其对应的段的关系就建立起来了。
注意:因为一个索引只对应两个段,所以只需要在索引的根页中记录这两个结构即可。
2.7 真实表空间对应的文件大小
上面这么多概念,独立表空间有那么大么?
一个新建的表对应的.ibd文件只占用了96K,6个页大小,一开始表空间占用的空间自然是很小,因为表里边都没有数据。
不过不要忘了这些.ibd文件是自扩展的,随着表中数据的增多,表空间对应的文件也逐渐增大。
三、系统表空间
系统表空间的结构和独立表空间基本类似,只不过由于整个MySQL进程只有一个系统表空间,在系统表空间中会额外记录一些有关整个系统信息的页,所以会比独立表空间多出一些记录这些信息的页。因为这个系统表空间最重要,相当于是表空间之首,所以它的表空间 ID(Space
ID)是0。
3.1 系统表空间的整体结构
系统表空间与独立表空间的一个非常明显的不同之处就是在表空间开头有许多记录整个系统属性的页,
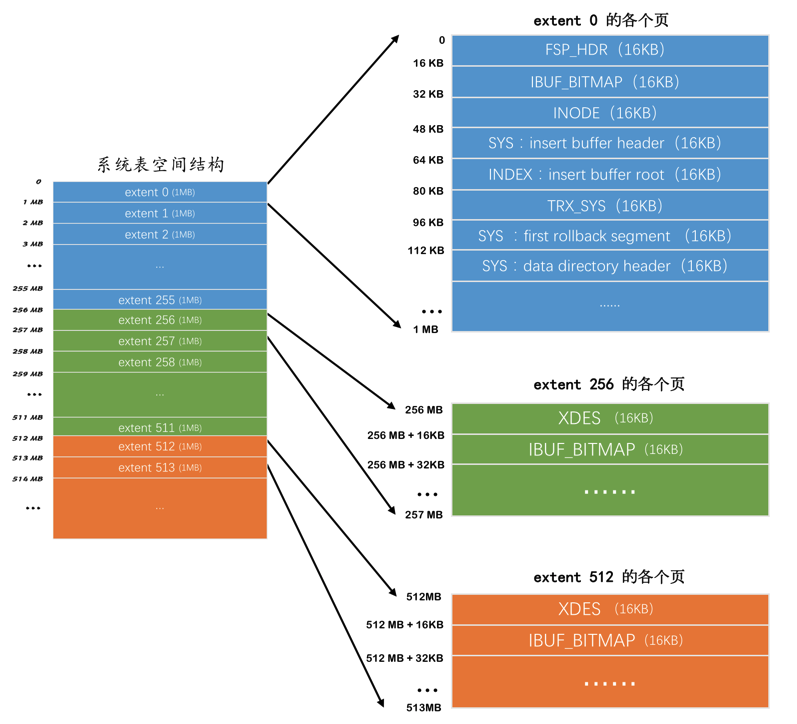
系统表空间和独立表空间的前三个页(页号分别为0、1、2,类型分别是FSP_HDR、IBUF_BITMAP、INODE)的类型是一致的,只是页号为3~7的页是系统表空间特有的,
| 页号 | 页类型 | 英文描述 | 描述 |
|---|---|---|---|
3 |
SYS |
Insert Buffer Header | 存储Insert Buffer的头部信息 |
4 |
INDEX |
Insert Buffer Root | 存储Insert Buffer的根页 |
5 |
TRX_SYS |
Transction System | 事务系统的相关信息 |
6 |
SYS |
First Rollback Segment | 第一个回滚段的页 |
7 |
SYS |
Data Dictionary Header | 数据字典头部信息 |
除了这几个记录系统属性的页之外,系统表空间的extent 1和extent 2这两个区,也就是页号从64~191这128个页被称为双写缓冲区(Doublewrite buffer)。
3.1.1 InnoDB数据字典
我们平时使用INSERT语句向表中插入的那些记录称之为用户数据,MySQL只是作为一个软件来为我们来保管这些数据,提供方便的增删改查接口而已。但是每当我们向一个表中插入一条记录的时候,MySQL先要校验一下插入语句对应的表存不存在,插入的列和表中的列是否符合,如果语法没有问题的话,还需要知道该表的聚簇索引和所有二级索引对应的根页是哪个表空间的哪个页,然后把记录插入对应索引的B+树中。
因此,MySQL除了保存着我们插入的用户数据之外,还需要保存许多额外的信息,这些数据也称为元数据。InnoDB存储引擎特意定义了一些列的内部系统表(internal
system table)来记录这些这些元数据:
| 表名 | 描述 |
|---|---|
SYS_TABLES |
整个InnoDB存储引擎中所有的表的信息 |
SYS_COLUMNS |
整个InnoDB存储引擎中所有的列的信息 |
SYS_INDEXES |
整个InnoDB存储引擎中所有的索引的信息 |
SYS_FIELDS |
整个InnoDB存储引擎中所有的索引对应的列的信息 |
SYS_FOREIGN |
整个InnoDB存储引擎中所有的外键的信息 |
SYS_FOREIGN_COLS |
整个InnoDB存储引擎中所有的外键对应列的信息 |
SYS_TABLESPACES |
整个InnoDB存储引擎中所有的表空间信息 |
SYS_DATAFILES |
整个InnoDB存储引擎中所有的表空间对应文件系统的文件路径信息 |
SYS_VIRTUAL |
整个InnoDB存储引擎中所有的虚拟生成列的信息 |
这些系统表也被称为数据字典,它们都是以B+树的形式保存在系统表空间的某些页中,其中SYS_TABLES、SYS_COLUMNS、SYS_INDEXES、SYS_FIELDS这四个表尤其重要,称之为基本系统表(basic
system tables),
SYS_TABLES表的列
| 列名 | 描述 |
|---|---|
NAME |
表的名称 |
ID |
InnoDB存储引擎中每个表都有一个唯一的ID |
N_COLS |
该表拥有列的个数 |
TYPE |
表的类型,记录了一些文件格式、行格式、压缩等信息 |
MIX_ID |
已过时,忽略 |
MIX_LEN |
表的一些额外的属性 |
CLUSTER_ID |
未使用,忽略 |
SPACE |
该表所属表空间的ID |
这个SYS_TABLES表有两个索引:
- 以
NAME列为主键的聚簇索引 - 以
ID列建立的二级索引
SYS_COLUMNS表的列
| 列名 | 描述 |
|---|---|
TABLE_ID |
该列所属表对应的ID |
POS |
该列在表中是第几列 |
NAME |
该列的名称 |
MTYPE |
main data type,主数据类型,即INT、CHAR、VARCHAR、FLOAT、DOUBLE等类型 |
PRTYPE |
precise type,精确数据类型,修饰主数据类型,比如是否允许NULL值,是否允许负数等 |
LEN |
该列最多占用存储空间的字节数 |
PREC |
该列的精度,默认值都是0 |
这个SYS_COLUMNS表只有一个聚集索引:
- 以
(TABLE_ID, POS)列为主键的聚簇索引
SYS_FIELDS表的列
| 列名 | 描述 |
|---|---|
INDEX_ID |
该索引列所属的索引的ID |
POS |
该索引列在某个索引中是第几列 |
COL_NAME |
该索引列的名称 |
这个SYS_INEXES表只有一个聚集索引:
- 以
(INDEX_ID, POS)列为主键的聚簇索引
Data Dictionary Header页
只要有了上述4个基本系统表,也就意味着可以获取其他系统表以及用户定义的表的所有元数据。比方说获取SYS_TABLESPACES这个系统表里存储了哪些表空间以及表空间对应的属性的过程:
- 到
SYS_TABLES表中根据表名定位到具体的记录,就可以获取到SYS_TABLESPACES表的TABLE_ID - 使用这个
TABLE_ID到SYS_COLUMNS表中就可以获取到属于该表的所有列的信息。 - 使用这个
TABLE_ID还可以到SYS_INDEXES表中获取所有的索引的信息,索引的信息中包括对应的INDEX_ID,还记录着该索引对应的B+数根页是哪个表空间的哪个页。 - 使用
INDEX_ID就可以到SYS_FIELDS表中获取所有索引列的信息。
问题:如何获取这4个表的元数据?
把这4个表的元数据,即有哪些列、哪些索引等信息硬编码到代码中,InnoDB取出了固定的页来记录这4个表的聚簇索引和二级索引对应的B+树位置,这个页就是页号为7的页,类型为SYS,记录了Data Dictionary Header,也就是数据字典的头部信息。除了这4个表的5个索引的根页信息外,这个页号为7的页还记录了整个InnoDB存储引擎的一些全局属性,

| 名称 | 中文名 | 占用空间大小 | 简单描述 |
|---|---|---|---|
File Header |
文件头部 | 38字节 |
页的一些通用信息 |
Data Dictionary Header |
数据字典头部信息 | 56字节 |
记录一些基本系统表的根页位置以及InnoDB存储引擎的一些全局信息 |
Segment Header |
段头部信息 | 10字节 |
记录本页所在段对应的INODE Entry位置信息 |
Empty Space |
尚未使用空间 | 16272字节 |
用于页结构的填充,没什么实际意义 |
File Trailer |
文件尾部 | 8字节 |
校验页是否完整 |
可以看到这个页里有Segment Header部分,意味着InnoDB把这些有关数据字典的信息当成一个段来分配存储空间。由于目前需要记录的数据字典信息非常少(可以看到Data Dictionary Header部分仅占用了56字节),所以该段只有一个碎片页,也就是页号为7的这个页。
Data Dictionary Header部分的各个字段:
Max Row ID:如果不显式的为表定义主键,而且表中也没有UNIQUE索引,那么InnoDB存储引擎会默认为我们生成一个名为row_id的列作为主键。因为它是主键,所以每条记录的row_id列的值不能重复。原则上只要一个表中的row_id列不重复就可以了,也就是说表a和表b拥有一样的row_id列也没什么关系,InnoDB只提供了这个Max Row ID字段,不论哪个拥有row_id列的表插入一条记录时,该记录的row_id列的值就是Max Row ID对应的值,然后再把Max Row ID对应的值加1,也就是说这个Max Row ID是全局共享的。Max Table ID:InnoDB存储引擎中的所有的表都对应一个唯一的ID,每次新建一个表时,就会把本字段的值作为该表的ID,然后自增本字段的值。Max Index ID:InnoDB存储引擎中的所有的索引都对应一个唯一的ID,每次新建一个索引时,就会把本字段的值作为该索引的ID,然后自增本字段的值。Max Space ID:InnoDB存储引擎中的所有的表空间都对应一个唯一的ID,每次新建一个表空间时,就会把本字段的值作为该表空间的ID,然后自增本字段的值。Mix ID Low(Unused):这个字段没什么用,跳过。Root of SYS_TABLES clust index:本字段代表SYS_TABLES表聚簇索引的根页的页号。Root of SYS_TABLE_IDS sec index:本字段代表SYS_TABLES表为ID列建立的二级索引的根页的页号。Root of SYS_COLUMNS clust index:本字段代表SYS_COLUMNS表聚簇索引的根页的页号。Root of SYS_INDEXES clust index本字段代表SYS_INDEXES表聚簇索引的根页的页号。Root of SYS_FIELDS clust index:本字段代表SYS_FIELDS表聚簇索引的根页的页号。Unused:这4个字节没用,跳过。
information_schema系统数据库
需要注意一点的是,用户是不能直接访问InnoDB的这些内部系统表的,除非直接去解析系统表空间对应文件系统上的文件。
InnoDB在系统数据库information_schema中提供了一些以innodb_sys开头的表,用于查看这些表的内容:
mysql> USE information_schema; |
在information_schema数据库中的这些以INNODB_SYS开头的表并不是真正的内部系统表(内部系统表就是以SYS开头的那些表),而是在存储引擎启动时读取这些以SYS开头的系统表,然后填充到这些以INNODB_SYS开头的表中。以INNODB_SYS开头的表和以SYS开头的表中的字段并不完全一样,但供参考已经足矣。
总结