Fork / Join 框架
什么是 Fork / Join 框架
Fork/Join 框架是 Java 7 提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
Fork 就是把一个大任务切分为若干子任务并行的执行,Join 就是合并这些子任务的执行结果,最后得到这个大任务的结果。分治思想。

工作窃取算法
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
为什么需要?
假如需要做一个比较大的任务,可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。
但是,有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
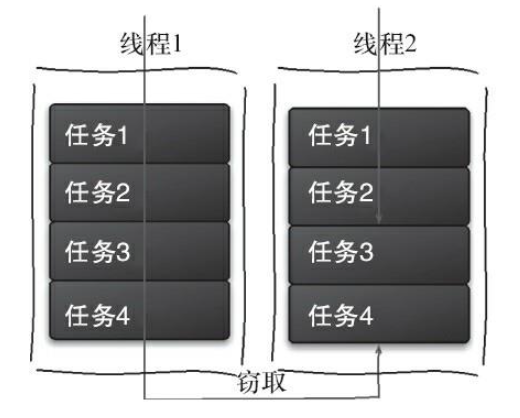
工作窃取算法的优点:充分利用线程进行并行计算,减少了线程间的竞争。
工作窃取算法的缺点:在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且该算法会消耗了更多的系统资源,比如创建多个线程和多个双端队列。
Fork / Join 框架的设计
步骤:
- 分割任务:不停分割,直到任务足够小
- 执行任务并合并结果
Fork/Join 使用两个类来完成以上两件事情:
ForkJoinTask:要使用 ForkJoin 框架,必须首先创建一个 ForkJoin 任务。它提供在任务中执行
fork()和join()操作的机制。通常情况下,不需要直接继承ForkJoinTask类,只需要继承它的子类,Fork/Join 框架提供了以下两个子类。RecursiveAction:用于没有返回结果的任务RecursiveTask:用于有返回结果的任务
ForkJoinPool:ForkJoinTask 需要通过 ForkJoinPool 来执行。任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
Fork / Join 框架的使用
需求:计算 1 + 2 + ... + 100 的结果
使用 Fork/Join 框架首先要考虑到的是如何分割任务,如果希望每个子任务最多执行两个数的相加,那么设置分割的阈值是 2,由于是 100 个数字相加,所以 Fork/Join 框 架会把这个任务 fork 成50个子任务,子任务一负责计算 1+2,子任务二负责计算 3+4……,然后再join子任务的结果。因为是有返回结果的任务,所以必须要继承RecursiveTask:
public class CountTask extends RecursiveTask<Integer> { |
Fork/Join 框架的异常处理
ForkJoinTask
在执行的时候可能会抛出异常,但是我们没办法在主线程里直接捕获异常,所以
ForkJoinTask
提供了isCompletedAbnormally()方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过
ForkJoinTask 的 getException方法获取异常。
if (task.isCompletedAbnormally()) { |
getException 方法返回 Throwable 对象,如果任务被取消了则返回CancellationException。 如果任务没有完成或者没有抛出异常则返回 null。