压缩列表是 Redis 为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构。 一个压缩列表可以包含任意多个节点,每个节点可以保存一个字节数组或者一个整数值。
压缩列表的最大特点,就是它被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存,而且会针对不同长度的数据,进行相应的编码,这种方法可以有效地节省内存开销。
相对的,压缩列表的缺陷也很明显:
- 不能保存过多的元素,否则查询效率会降低;
- 新增或者修改某个元素时,压缩列表占用的内存空间需要重新分配,甚至可能引发连锁更新的问题。
因此 Redis 对象包含的元素数量较少,或者元素值不大的情况下才会使用压缩列表作为底层数据结构。
压缩列表结构设计

其中有几个字段的含义:
zlbytes,记录整个压缩列表占用字节数;zltail,记录压缩列表「尾部」节点距离起始地址由多少字节,即列表尾的偏移量;zllen,记录压缩列表包含的节点数量;zlend,标记压缩列表的结束点,固定值 0xFF(十进制 255)。
由此,在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头的三个字段
(zllen) 的长度直接定位,时间复杂度为
O(1);但是查找其他元素时,只能逐个遍历查找,时间复杂度为
O(N),因此压缩列表不适合保存过多的元素。
「压缩列表节点(entry)的结构」
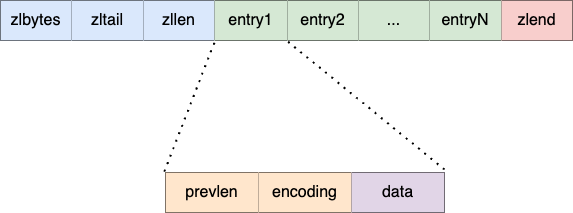
prevlen,记录「前一个节点」的长度,目的是为了实现倒序遍历;encoding,记录了当前节点实际数据的「类型和长度」,类型主要有两种:字符串和整数。data,记录了当前节点的实际数据,类型和长度都由encoding决定。
其中 prevlen 属性的空间大小跟前一个节点长度值有关:
- 如果前一个节点的长度小于 254 字节,那么 prevlen 属性占用 1 字节的空间;
- 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性占用 5 字节空间。
encoding
属性的空间跟数据是否是字符串还是整数,以及字符串的长度有关:
- 如果当前节点的数据是整数,则 encoding 会使用 1 字节的空间进行编码,也就是 encoding 占用 1 字节空间;通过 encoding 得到整数类型,就可以得到整数数据的实际空间大小;
- 如果当前节点的数据是字符串,根据字符串的长度大小,encoding 会使用 1字节 / 2字节 / 5字节的空间进行编码,其中前两个 bit 标识数据的类型,后续的 bit 标识字符串数据的实际长度,即 data 的长度。
连锁更新
压缩列表新增某个元素或者修改某个元素时,如果空间不够存放,压缩列表占用的内存空间就需要重新分配,而当新插入的元素较大时,可能会导致后续元素的
prevlen
占用空间都发生变化,从而引发「连锁更新」的问题,导致每个元素的空间都需要重新分配,造成访问压缩列表的性能下降。
【🌰栗子】
因为压缩列表节点中的 prevlen 属性的空间大小和前一个节点的长度值有关:
- 如果前一个节点的长度小于 254 字节,那么 prevlen 属性占用 1 字节的空间;
- 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性占用 5 字节空间。
现有一个压缩列表中多个连续的、长度在 250 ~ 253 之间的节点:
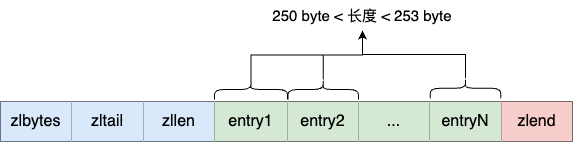
因为这些节点长度值小于 254 字节,所以 prevlen 属性需要用
1 字节的空间来保存这个长度值。现在,将一个长度大于等于 254
字节的新节点加入到压缩列表的表头,即新节点将成为 entry1 的前置节点,因为
entry1 节点的 prevlen 属性只有 1
个字节大小,无法保存新节点的长度,此时就需要对压缩列表的空间重分配操作,并将
entry1 节点的 prevlen 属性从原来的 1 字节大小扩展为 5
字节大小。
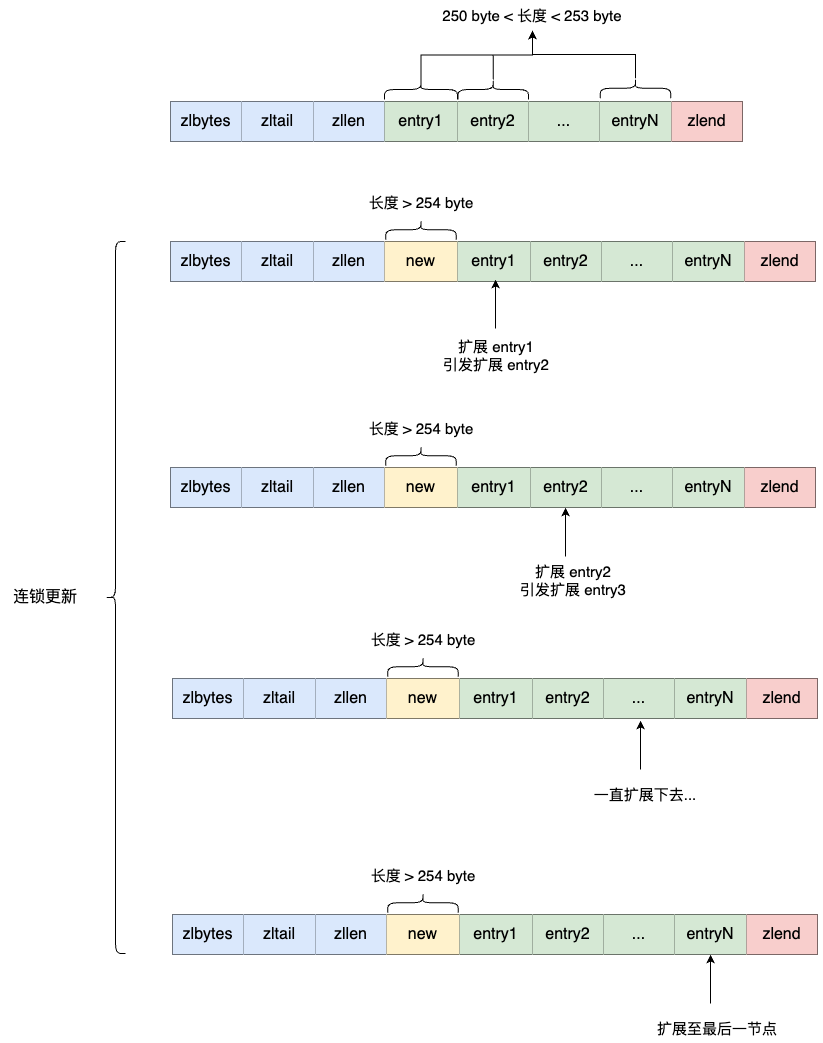
entry1 原本的长度在 250~253 之间,因为刚才的扩展空间,此时 entry1
的长度就大于等于 254 了,因此原本 entry2 保存 entry1 的
prevlen 属性也必须从 1 字节扩展至 5
字节大小。后续节点依次发生扩展。这种在特殊情况下产生的连续多次空间扩展操作就叫做「连锁更新」。
压缩列表的缺陷
压缩列表的空间扩展操作,即重新分配内存,这过程可能会发生连锁更新,连锁更新一旦发生,就会导致压缩列表占用的内存空间要多次重新分配,这就会直接影响到压缩列表的访问性能。因此,虽然压缩列表紧凑型的内存布局能节省内存开销,但是如果保存的元素数量增加或者元素占用空间增大,就会导致内存重新分配,甚至出现「连锁更新」的问题。
因此,压缩列表只会用于保存的节点数量不多的场景,只要节点数量足够小,即使发生连锁更新,也是可以接受的。