在 MQ 中,「消息不丢」和「消息不重」一直都是一对孪生兄弟。消息不重复也是非常重要的,例如在金融场景,发送了一条给同一个账户扣减余额的消息,如果这条消息被重复消费了,多次扣除,这是无法容忍的。
一般性的思路是:只保证消息只发送一次不就好了嘛,也就是保证生产者对同一条消息仅发送一次给 Broker,然后消费者从 Broker 自然只能获取到一次消息,那么自然就能够保证消息不会重复。但是这种方案从目前 MQ 的实现来看是无法实现的,消息一定会出现重复的情况!下面就来分析下。
消息一定会重复
发送消息的流程
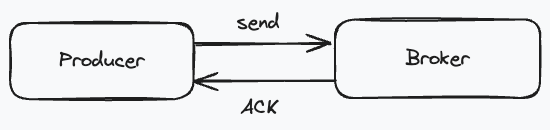
生产者发送消息给 Broker 后,需要等待 Broker 响应的 ACK 才能够确保消息已经被 Broker 存储了。通过「请求-应答」的模式来确保消息不会丢失。
现在假设 Broker 已经成功接收了消息并成功存储了,但是返回给生产者的 ACK 因为网络原因 丢失了,生产者并没有接收到这条消息的 ACK,那么生产者为了确保消息不丢失,只能再次发送这条消息。在这种情况下,同一条消息就被发送了两次,Broker 上就存在了两条一样的消息。
问题:既然为了保证消息不丢失,生产者没有好的解决方案,为什么不让 Broker 来过滤这些重复消息呢?
理论上来说确实可以这样实现,但是实际使用 MQ 的时候,消息的体量都会比较大,Broker 本身的负载就不低了,如果还要加上去重功能,那么势必需要解析接收到的所有消息,然后进行比对,这会进一步加重 Broker 的负担,在高并发的情况下会大大降低 MQ 的性能。而且市面上的 MQ 也确实没有这么实现。
因此,从发送流程来看,无法避免消息不重复发送,如果发生网络抖动等原因,Broker 很可能会存储多条一摸一样的消息。
消费消息的流程
从消费消息的流程来看,即使 Broker 实现了消息去重的功能,也无法保证同一条消息一定只被消费者消费一次。
在 RocketMQ 中,消费者是通过提交消费点位来跟 Broker 同步已经消费到的位置的。在集群模式下,消费点位是存储在 Broker 上的,并且是消费者在拉取消息的时候顺带把此时的消费点位提交给 Broker。
现在假设消费者在消费完消息后,宕机了,此时消费点位还没有提交到 Broker,然后发生了队列 Rebalance,另一个消费者顶替了这个队列的消费,此时就产生了消息的重复消费。
因此,不论是从生产消息、存储消息、消费消息三个方向来看,都无法保证消息不重复。那么该如何去实现消息的不重复呢?
实际上消息无法保证不重复,但是我们可以保证它仅被幂等消费来达到仅消费一次的效果。
消息的幂等消费
幂等其实是数学上的概念,即f(f(x)) = f(x),对于程序而言就是一个方法被同样的入参调用一次和多次产生的影响是一样的。
因此,即然无法保证消息的不重复,那我们可以利用幂等来避免重复消费产生的影响。
那么如何保证消息的幂等消费呢?
改造业务
在项目初期或者新 feature 刚开始设计的时候,就可以考虑幂等的设计来满足业务需求,就比如执行数据库 update 语句的时候可以加一些版本号的判断,比如现在有一个消费消息业务逻辑:给用户加积分,并且讲订单的状态从待完成变成已完成。
首先我们要调整下执行的顺序,不是先加积分,而是先改变订单的状态,执行:
update `order` set `status` = 1 where `order_no` = xxx and `status` = 0; |
添加一个 status=0的判断,如果消费已经被消费过,那么
order_no=xxx 这个订单的 status 肯定已经是 1
了,这样一来这个 update 执行之后影响的行数是
0,通过这个我们就能够确定时候是重复消费了。如果是重复消费,流程直接终止,这样后面给用户加积分这种不好利用
update
实现幂等操作的业务,日前前置其他业务处理也能够实现幂等,重复消费也不会使得用户积分被重复添加。
在业务上做幂等改造就需要抓住这些点,将一些容易完成幂等改造的业务前置处理,并添加一个约束条件,提前终止重复消费,使得完整的大业务都实现幂等。
记录流水
上面所说的改造业务仅限初期,但是往往很多需求不是初期就有的,而是后面迭代的,此时整个业务流程基本上已经定型了,业务逻辑可能已经很复杂,不太好改造出如上述 update 这样的语句来满足当前的业务需求。
此时可以利用数据库的唯一索引约束来保证消费的幂等消息。
例如可以给消息加一个事务 ID,这个事务 ID 是全局唯一的,数据库表记录给这个事务 ID 添加唯一索引,当第一次处理完这条消息时,同时在数据库中存储这条消息的处理记录,如果后面有重复消息,那么插入一定是会抛出错误的,这样一来就可以避免消息的重复消费,从而实现幂等。
具体操作起来大致有两个方向:
- 利用当前的已有的字段来作为唯一索引,比如订单的处理,订单号肯定是唯一的,此时就不需要额外添加一个事务 ID 的字段;
- 如果没有合适的已有字段,那么就扩展一个事务 ID 字段来满足要求。
如果当下的业务表结构或者处理流程不方便扩展新的字段,那么消费端可以添加一张流水表来存储新的事务 ID 字段,将这张流水表的写入和业务处理放在一个事务中,这样就可以保证业务事务执行成功后流水表一定添加成功,这样就可以通过流水表实现消息的幂等了。
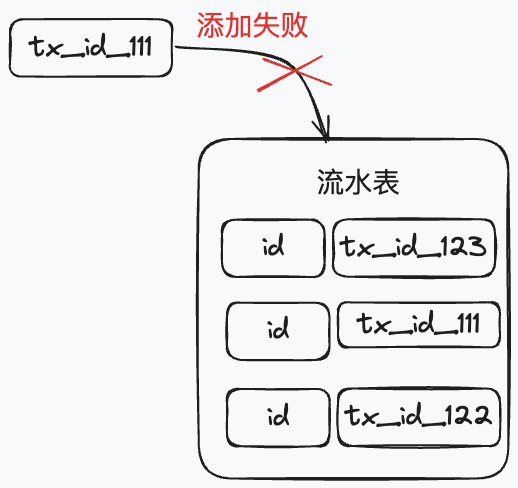
同理,Redis
也能实现幂等的功能,相比数据库的唯一索引需要更改表结构或者新加一张流水表,Redis
更加简单,利用 SETNX 这个命令就可以实现幂等消费。
同样也是利用全局唯一值来标记这条消息,例如订单号或者定义的事务 ID,每次在业务逻辑执行之前先利用 SETNX 来判断下,如果已经插入就直接返回,反之正常执行业务逻辑。
但是这个方案有一个问题,如果唯一值插入 Redis 后,消费者宕机了,业务逻辑并没有执行成功,那么即使由另一个消费者顶上消费这条消息,由于 Redis 中还存储着这个唯一值,会使得这条消息被跳过,这样这条消息就跟丢失了是一样的。