延迟消息,即生产者给一条消息设置延迟时间,看起来消息是延迟了一段时间之后才发送出去,然后消费者才能够消费到这条消息。
常见的场景就是订单自动取消的场景,下单之后 15min 没有支付订单,这个订单就会被自动取消。
那延迟消息该如何去实现?
思考下如何设计?
正常生活中,如果我们要延迟做一件事情,比如「半个小时后发布」,那么我们可能就会现在定一个半个小时的闹钟,半个小时后提醒我们该发布啦。 映射到消息上来,是不是我们发送一条延迟消息,实际上也是在生产者内部设置一个“闹钟”,等到了时间再投递出去呢?
答案很明显不是的,如果让生产者来设定这个闹钟,那么成千上万个延迟消息的管理,需要多少个“闹钟”,且不说单设置“闹钟”就会给生产者带来很大的压力,那些没有发送出去的延迟消息堆积在生产者端,OOM是迟早的事。
所以我们需要明确一点:延迟消息也是立马被投递出去的,而不是等到时间到了才被发往 Broker。
好了,现在压力给到了 Broker,这也符合 Broker 的设定:承载大量消息,削峰填谷。现在 Broker 接收到延迟消息,需要控制未到时间的消息不会被消费者消费到,等到了时间之后才会被消费者拉取消费。
但是,Broker 也承载不了一条延迟消息一个“闹钟”的机制,因为消息的量级可能会很大(十万、百万、千万),如果每一条消息一个“闹钟”,Broker 也是顶不住的。
在 RocketMQ 中,消息投递到 Broker 都是按照顺序存储在 commitlog 中的,然后顺序的映射到 comsumeQueue 供消费者消费。
假设有一条消息的延迟时间是1天,它被夹在两条不延迟的消息中间,如果按照顺序来看,后面那条消息就被堵住了。
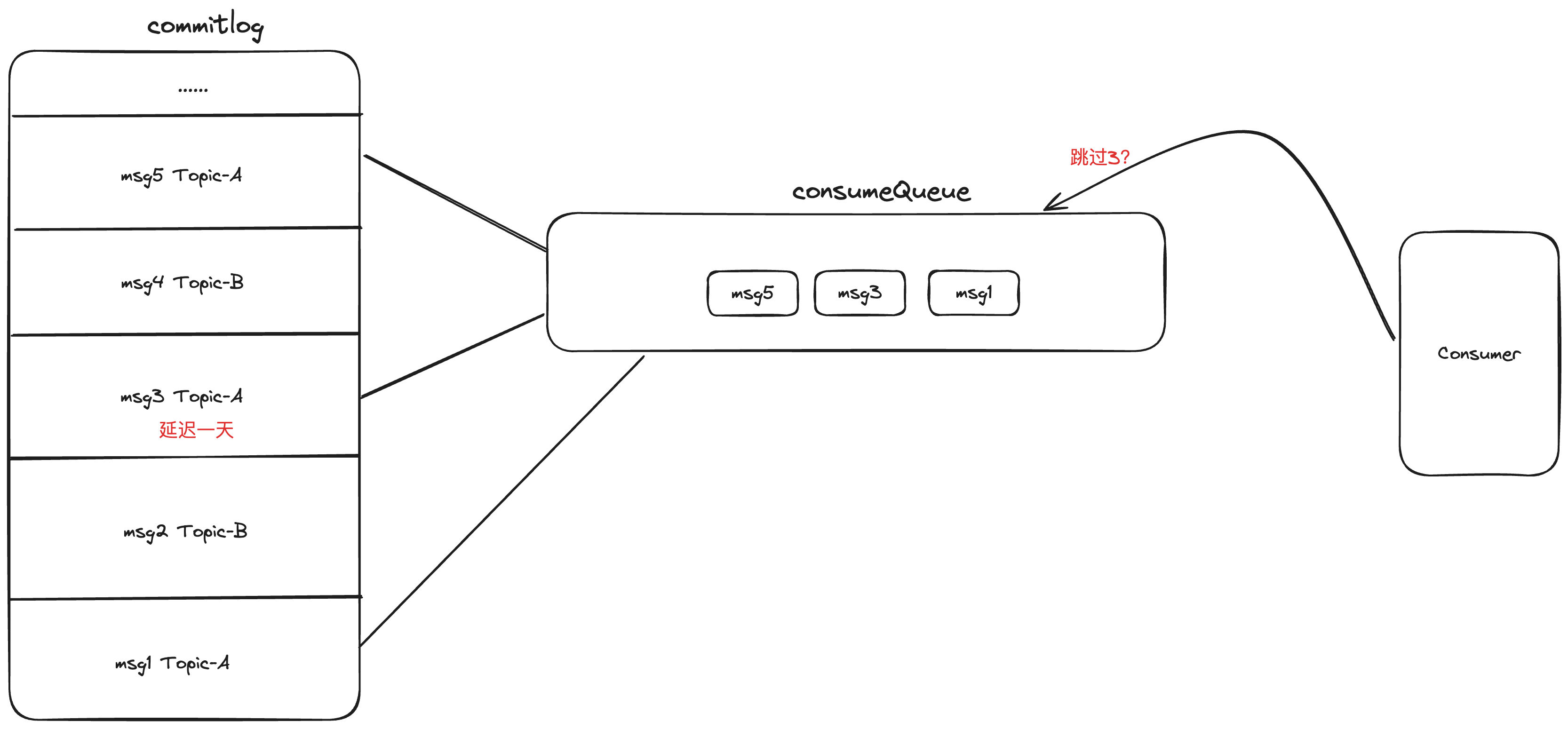
因为消息的消费是按照 offset 确定位置的,当消费到这条延迟消息,由于时间还没到,所以不让消费,此时总不能够堵住不让消费后续的消息吧,如果要消费后续的消息,那么 offset 需要加1。
加1当然没问题,但是 offset+1 后,就顺着后面的消息消费了,offset 一直递增,然后等延迟消息到了时间,再把 offset 调回来?等消费完对应的延迟消费,再调回去?
这样的设计不仅怪、复杂,整体的性能也会差很多!
因为计算机领域有局部性原理,大概的意思就是最近访问到的数据,它附近的数据近期也会被访问,所以操作系统等层面上都会做预加载的缓存起来。 问题来了,如果采用现有的这种跳来跳去的设计,就很难利用好预加载的缓存,去磁盘读取数据就很慢。
所以这样的设计是无法利用好现有 commitlog 的设计的,那么 RocketMQ 是如何设计的呢?
简略了解 RocketMQ 的设计
针对于“闹钟”撑爆的问题,RocketMQ 直接给定了一些延迟时间,即生产者无法灵活的自定义延迟时间,而是固定的几个延迟来供生产者选择:
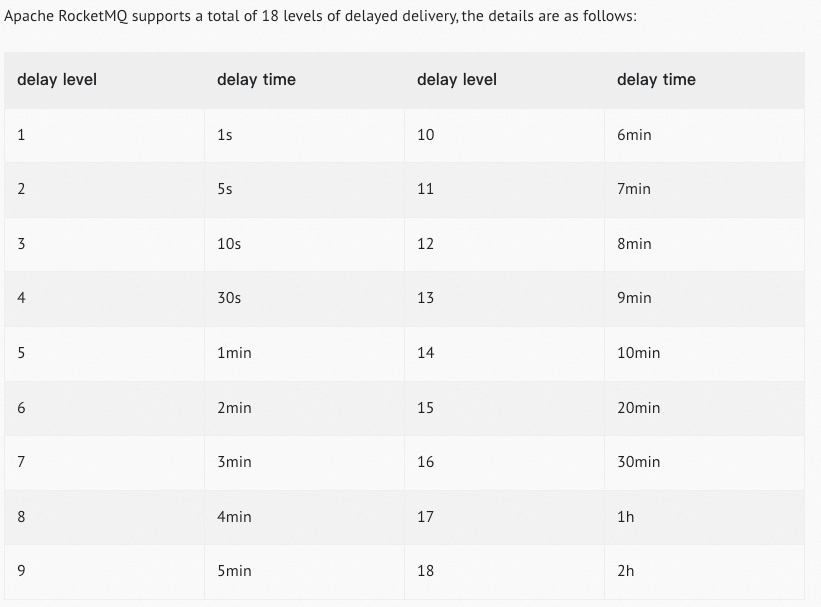
可以看到,一共有 18 个延迟时间供选择,基本上能够满足日常业务的使用。这样一来,延迟消息也有统一归类和约束,便于管理。
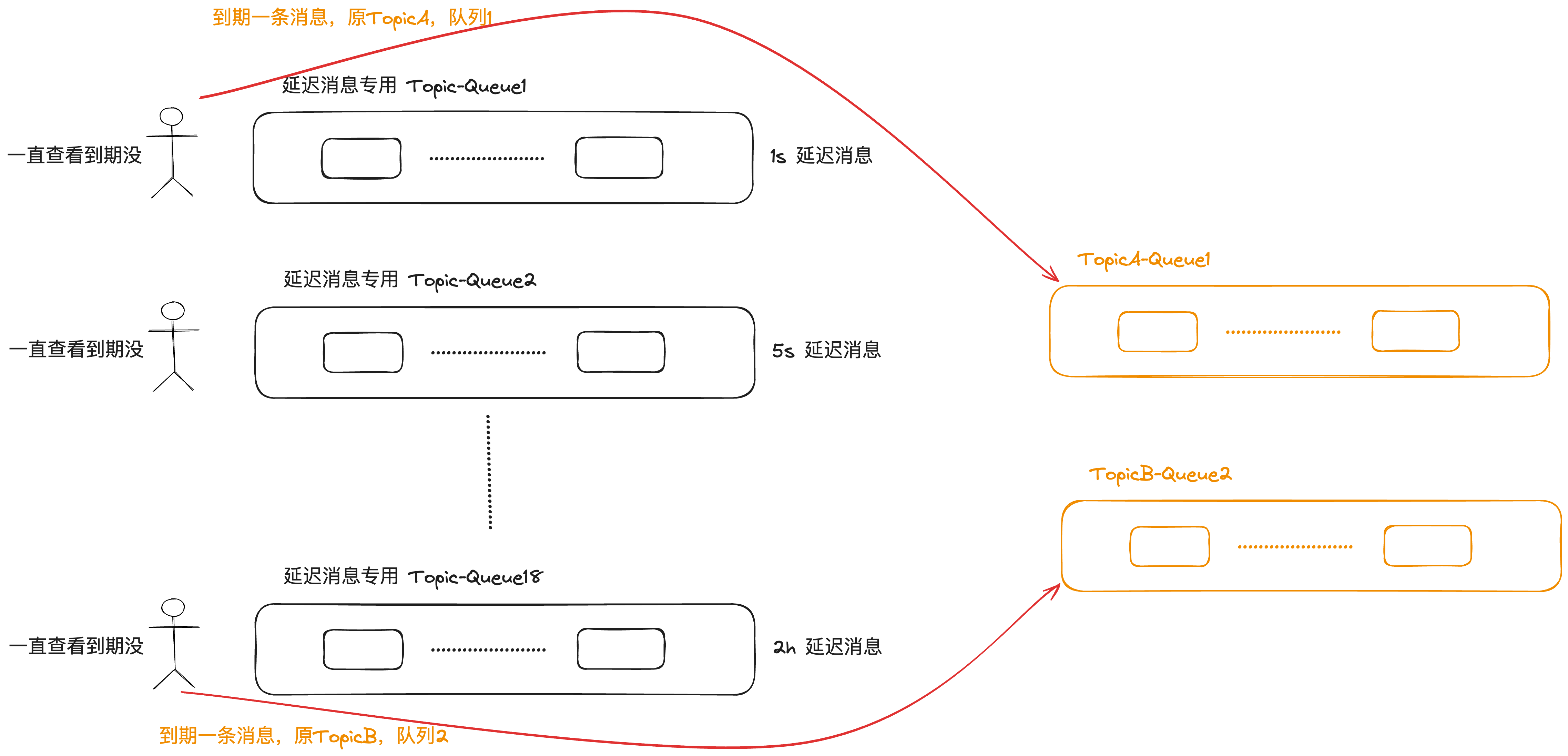
虽然说归类了延迟消息,但是每个 level 的消息共用一个“闹钟”也是无法满足需求的。因此 RocketMQ 给每一个 level 都雇佣了一个“人”,定期查看是否有到期的消息,如果到了立马让消息消费者消费。
至于说复用 commitlog 的问题,RocketMQ 专门创建了用于存放延迟消息的 Topic,延迟消息会先发往这个 Topic,消费者并不会订阅这个 Topic,因此此时消费者无法消费到这条消息。等到延迟消息到达时间后,Broker 将该延迟消息发往原有的 Topic,此时消费者就可以从原有 Topic 中消费到这条消息。
也就是说 RocketMQ 创建了专门的 Topic 用来存储延迟消息,那么延迟消息的存储就能够复用 commitlog 这一套模型,消息也会被分发到 ConsumeQueue。
不同 level 的消息会被存放在这个 Topic 不同的队列中,也就是说这个 Topic 一共有 18 个队列对应 18 个 level。然后会有一个定时线程去每个队列按序检查消息是否到时间了,如果到了就发到消息原先的 Topic。
深入了解 RocketMQ 的设计
延迟消息的发送很简单,仅需要设置一个 delayTimeLevel
即可:
Message message = new Message("TestTopic", ("Hello scheduled message " + i).getBytes()); |
Broker 接收到这条消息,发现 delayTimeLevel
设置了值,就知道它是一条延迟消息,于是来了一招偷梁换柱。
把消息的原 Topic 和对应的队列 ID 保存在消息的扩展属性中,然后将消息的
Topic 设置成
SCHEDULE_TOPIC_XXXX,并且根据消息的延迟时间等级选择对应的队列。
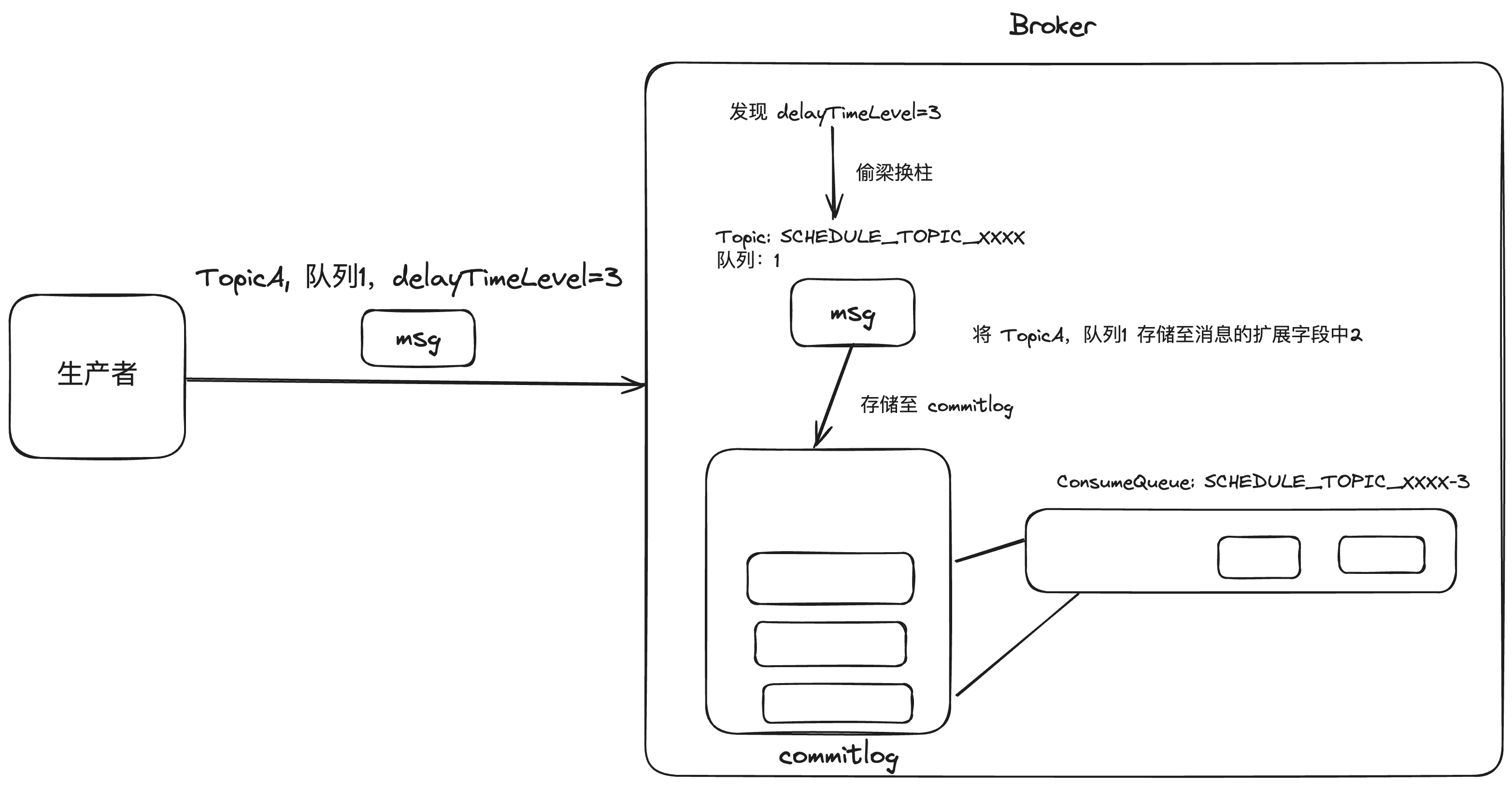
这样一来消息就存储好了。
然后 Broker
起一个定时线程池,里面一共有18个核心线程,这个线程池的任务就是定时调度
SCHEDULE_TOPIC_XXXX下的每个队列的消息,一旦有到期的消息,就分发到原
Topic 供消费者消费。
具体的,每个队列都会对应被创建一个任务给到线程池,这些任务的内容就是根据传入的队列ID,得到对应的
ConsumeQueue 和对应的 offset。Broker 会定时保存
SCHEDULE_TOPIC_XXXX下 ConsumeQueue 的消费 offset。得到
ConsumeQueue 和
offset,对应就能获取到延迟消息,此时判断该消息是否过期,如果过期,就从消息扩展属性中获取原
Topic 和对应队列 ID,然后投递到原队列中。
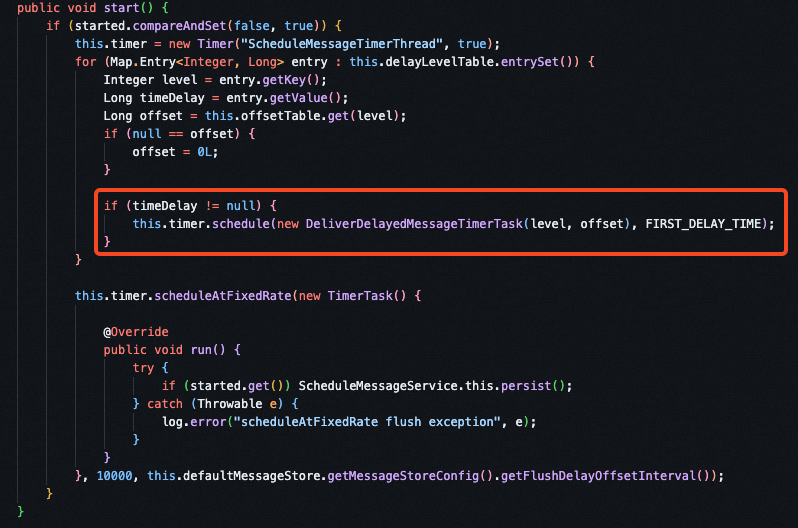
在代码中的实现是立马新建一个任务给到线程池,延迟时间是 100ms,任务的入参会被更新成更新后的 offset,这样线程就会继续消费后面的消息,如此往复循环。当然,如果拿到的延迟消息还未到时间,那么 offset 不变,也会立马新建一个任务塞入到线程池中,这样 100ms 后又会来看这条延迟消息是否到期。
可以看到,整个延迟消息设计就加了一个线程池,很巧妙的复用了正常消息的 commitlog 和 consumeQueue 的存储机制,且利用发布订阅机制,改变消息的 Topic 来使得消费者无法消费到未到时间的消息。到时间了又投递回原 Topic 使得消费者可以消费到期的消息。
设计存在的问题
从实现的层面来看,大大减少了延迟消息的开发复杂度,但是这样的实现对延迟时间来说是不准的。
首先,同一个延迟 level 的消息都入同一个队列,然后上一个延迟消息处理完之后,继续处理下一个,如果同一时刻有大量的同一个 level 的延迟消息产生,那么它们都堆积在一个队列里面,一个一个处理,这样一来即使后面的消息到时间了也得排队等着。这样的机制就做不到非常实时。
并且从 SCHEDULE_TOPIC_XXXX分发到原 Topic 之后,假设原
Topic
本身就有很多的消息堆积了,那么等到消费者消费这条消息的时候,时间也是有大大延迟的。
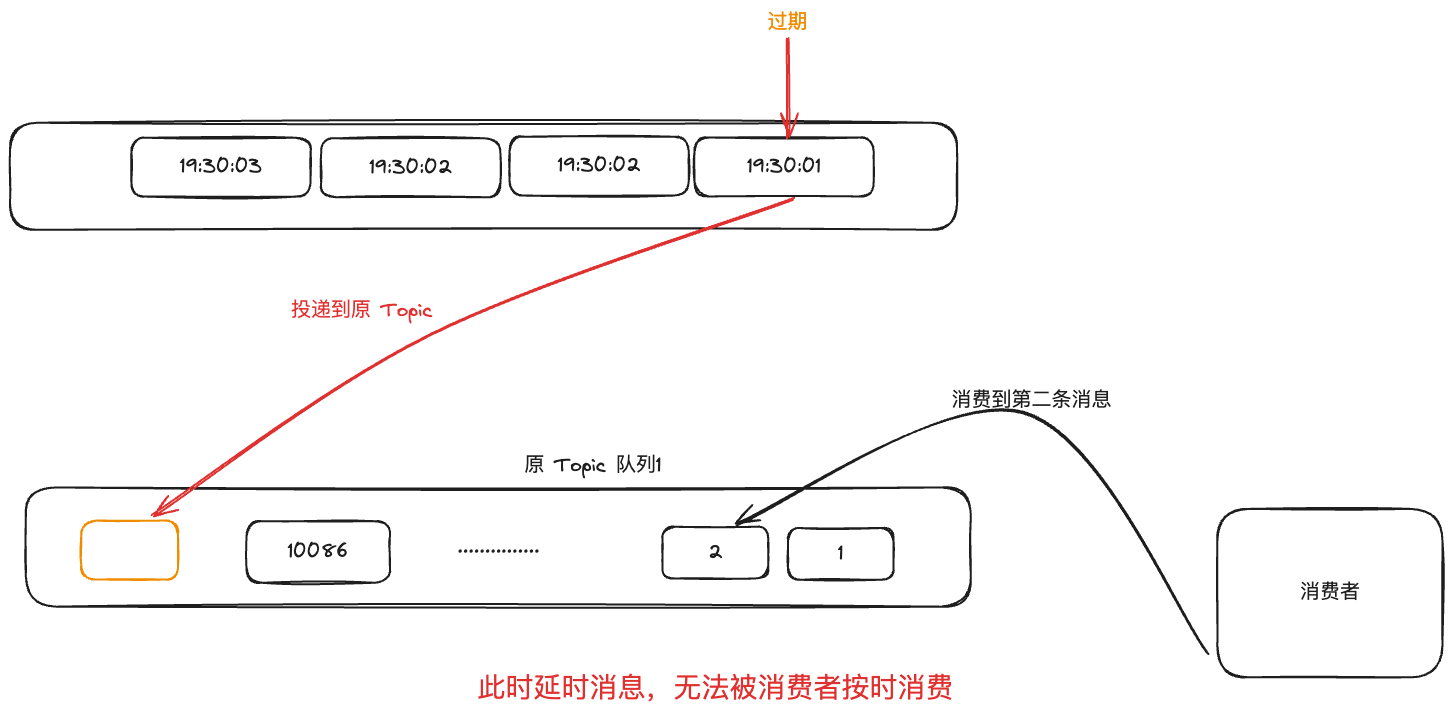
当然,本身在大流量下对时间的把控是无法做到很准确的,不论用什么方式,都会有延迟,无非就是延迟精度多少的问题。
有一种比较好的定时结构就是时间轮了。