问题:如何改进 LRU 算法?
传统 LRU 算法存在的问题:
- 「预读失效」导致缓存命中率下降
- 「缓存污染」导致缓存命中率下降
那么 MySQL 和 Linux 是通过改进 LRU 算法来避免这两个问题导致的缓存命中率下降的。
Redis 是通过实现 LFU 算法来避免因为「缓存污染」导致的缓存命中率下降问题的。
问题:如何改进 LRU 算法?
传统 LRU 算法存在的问题:
那么 MySQL 和 Linux 是通过改进 LRU 算法来避免这两个问题导致的缓存命中率下降的。
Redis 是通过实现 LFU 算法来避免因为「缓存污染」导致的缓存命中率下降问题的。
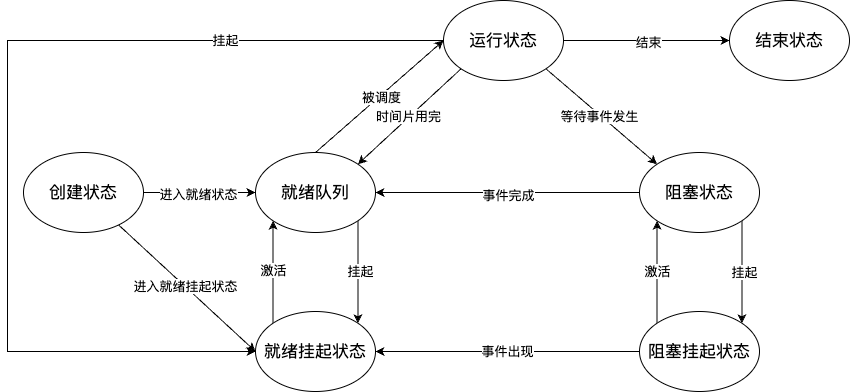
PS:挂起是指进程没有占用实际的物理内存空间的情况。
导致进程挂起的原因:
- 进程使用的内存空间不在物理内存
- 通过 sleep 让进程间歇性挂起
- 用户希望挂起一个程序的执行,比如 Linux 中使用
Ctrl+Z挂起进程
开发者编写的代码只是一个存储在硬盘的静态文件,通过编译后就会生成二进制可执行文件,当运行该可执行文件后,它会被转载到内存中,接着 CPU 会执行程序中的每一条指令,这个运行中的程序就被称之为「进程」。
HTTP/0.9 -> HTTP/1.0 -> HTTP/1.1 -> HTTP/2 -> HTTP/3,一代更比一代强,一浪更比一浪强,前浪拍死在沙滩上!
Dict 字典,哈希表,是一种保存键值对的数据结构。哈希表中的每个键都是独一无二的,程序可以在哈希表中根据 key 查找与之关联的 value,或者通过 key 来更新 value,又或者根据 key 来删除整个 kv 键值对。
哈希表的优势在于它查询的时间复杂度是 O(1),靠的就是 hash 函数,能够快速定位数据在表中的位置,其次,哈希表实际上是数组,所以可以通过索引值快速查找数据。然而,由于哈希表的大小是有限的,而数据是在不断增多的,随之而来的风险就是哈希冲突,Redis 通过「链地址法」来解决哈希冲突。
跳表是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。
Redis 中 Zset 对象的底层实现用到了跳表,跳表支持平均 O(logN)、最坏 O(N) 复杂度的节点查找,还可以通过顺序性操作来批量处理节点。
typedef struct zset { |
zset
结构体里有两个数据结构,一个是跳表,一个是哈希表。这样的好处是既能进行高效的范围查询,也能进行高效单点查询。zset
对象在执行数据插入或是数据更新的过程中,会依次在跳表和哈希表中插入或更新相应的数据,从而保证了跳表和哈希表中记录的信息一致。zset
对象能支持范围查询(如 ZRANGEBYSCORE
操作),这是因为它的数据结构设计采用了跳表,又能以常数复杂度获取元素权重(如
ZSCORE 操作),这是因为它同时采用了哈希表进行索引。
首先需要明确的是这件事和内存泄露相关。
内存泄露指的是当某一个对象不再使用时,其占用的内存无法回收的情况。
因为通常情况下,当一个对象不再使用(有用)的情况下,垃圾回收起 GC 应该将这部分内存回收掉,这样的话就可以让这部分内存被重新使用,否则,如果对象没有用却不能回收,这样只会导致垃圾对象积压,以至于可用内存越来越少,最后出现 OOM 的错误。
压缩列表是 Redis 为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构。 一个压缩列表可以包含任意多个节点,每个节点可以保存一个字节数组或者一个整数值。
压缩列表的最大特点,就是它被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存,而且会针对不同长度的数据,进行相应的编码,这种方法可以有效地节省内存开销。
相对的,压缩列表的缺陷也很明显:
因此 Redis 对象包含的元素数量较少,或者元素值不大的情况下才会使用压缩列表作为底层数据结构。