消费者订阅了某个 Topic 后,就能够从 Broker 获取所有关于这个 Topic 的消息,但是有时候并不是有关这个 Topic 的消息都是消费者感兴趣的。
比如拿游戏来举例子,游戏爱好者们都喜欢游戏相关的信息(订阅了游戏 Topic),但是有些喜欢MC、有些喜欢COC,于是乎他们也只想获取他们喜欢的游戏的相关消息,所以需要做消息过滤。
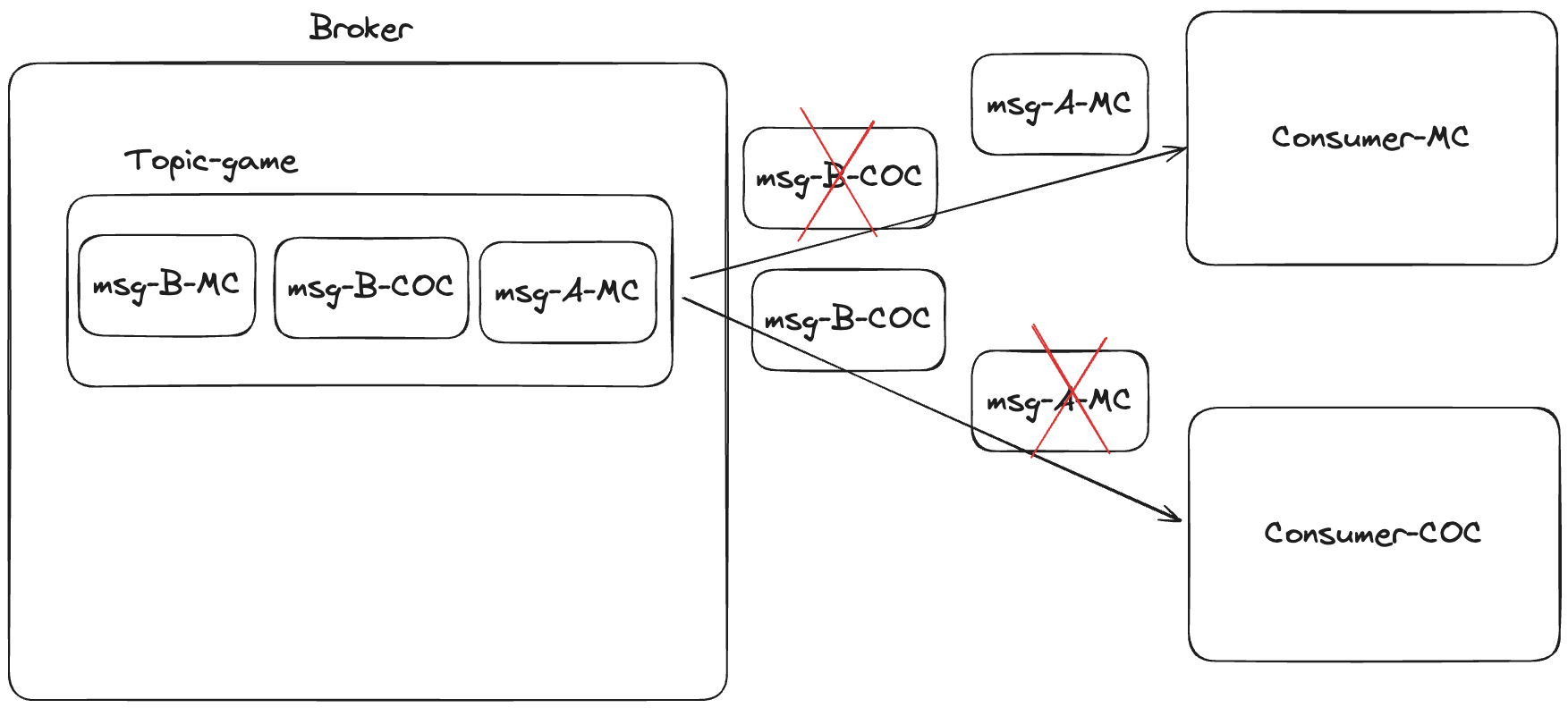
消费者订阅了某个 Topic 后,就能够从 Broker 获取所有关于这个 Topic 的消息,但是有时候并不是有关这个 Topic 的消息都是消费者感兴趣的。
比如拿游戏来举例子,游戏爱好者们都喜欢游戏相关的信息(订阅了游戏 Topic),但是有些喜欢MC、有些喜欢COC,于是乎他们也只想获取他们喜欢的游戏的相关消息,所以需要做消息过滤。
事件 (Event) 通知是 Spring 核心功能之一。

其中核心的类
org.springframework.context.ApplicationEvent,该类定义了整个
Spring 应用中的各种事件。
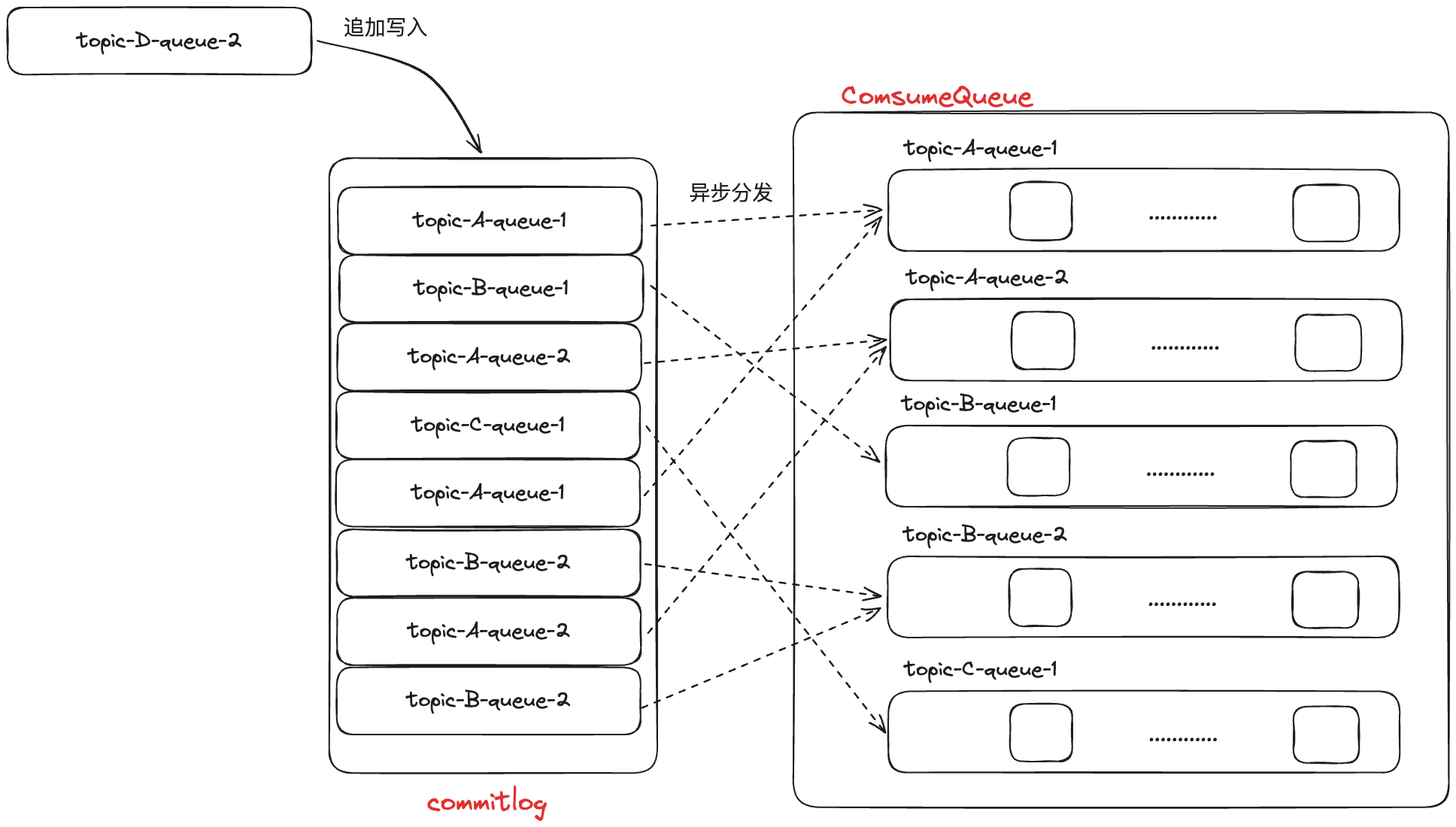
RocketMQ 采用多 Topic 混合存储一个文件的方式来保存消息,即一个 commitlog 文件中会包含分给此 Broker 的所有消息,不论消息属于哪个 Topic 的哪个 Queue。
延迟消息,即生产者给一条消息设置延迟时间,看起来消息是延迟了一段时间之后才发送出去,然后消费者才能够消费到这条消息。
常见的场景就是订单自动取消的场景,下单之后 15min 没有支付订单,这个订单就会被自动取消。
那延迟消息该如何去实现?
这篇文章来介绍下 RocketMQ 事务消息的作用以及他的实现原理。
事务消息也是分布式事务的一种解决方案,在生产上也很常用。
简单来说,事务就是指一系列操作要么全部执行成功,要么全部执行失败,不会出现一些成功一些失败的情形。
【栗子🌰】转账:A 给 B 转账 1000 元,那么 A 账户扣款 1000 和 B 账户进账 1000 这两个操作必须全部成功,或者全部失败,否则就破坏了数据的一致性。
严格来说,事务必须满足 ACID 特性,这里不再赘述。
对于
git clone, pull, push等基础用法本文不再赘述。
场景:需要在项目中加一个不需要提交到远程仓库的文件。
那我们只需要将这个文件写到 .gitignore
文件中就好了,但是这个文件需要执行相应命令后才会生效:
git rm -r --cached . |
注意:上述命令中,
.代表当前目录下的所有文件,可以按需换成对应的单个文件名。
本文主要介绍 Broker 底层的存储原理,理解什么是「刷盘」以及 RocketMQ 为了底层存储性能的提升做了哪些事情。
每次谈到网络 I/O 的时候,总会出现几个容易令人混淆的概念:同步 / 异步、阻塞 / 非阻塞 的区别。
让我们来盘一盘这几个概念!