RocketMQ 的消息存储
RocketMQ 采用多 Topic 混合存储一个文件的方式来保存消息,即一个 commitlog 文件中会包含分给此 Broker 的所有消息,不论消息属于哪个 Topic 的哪个 Queue。
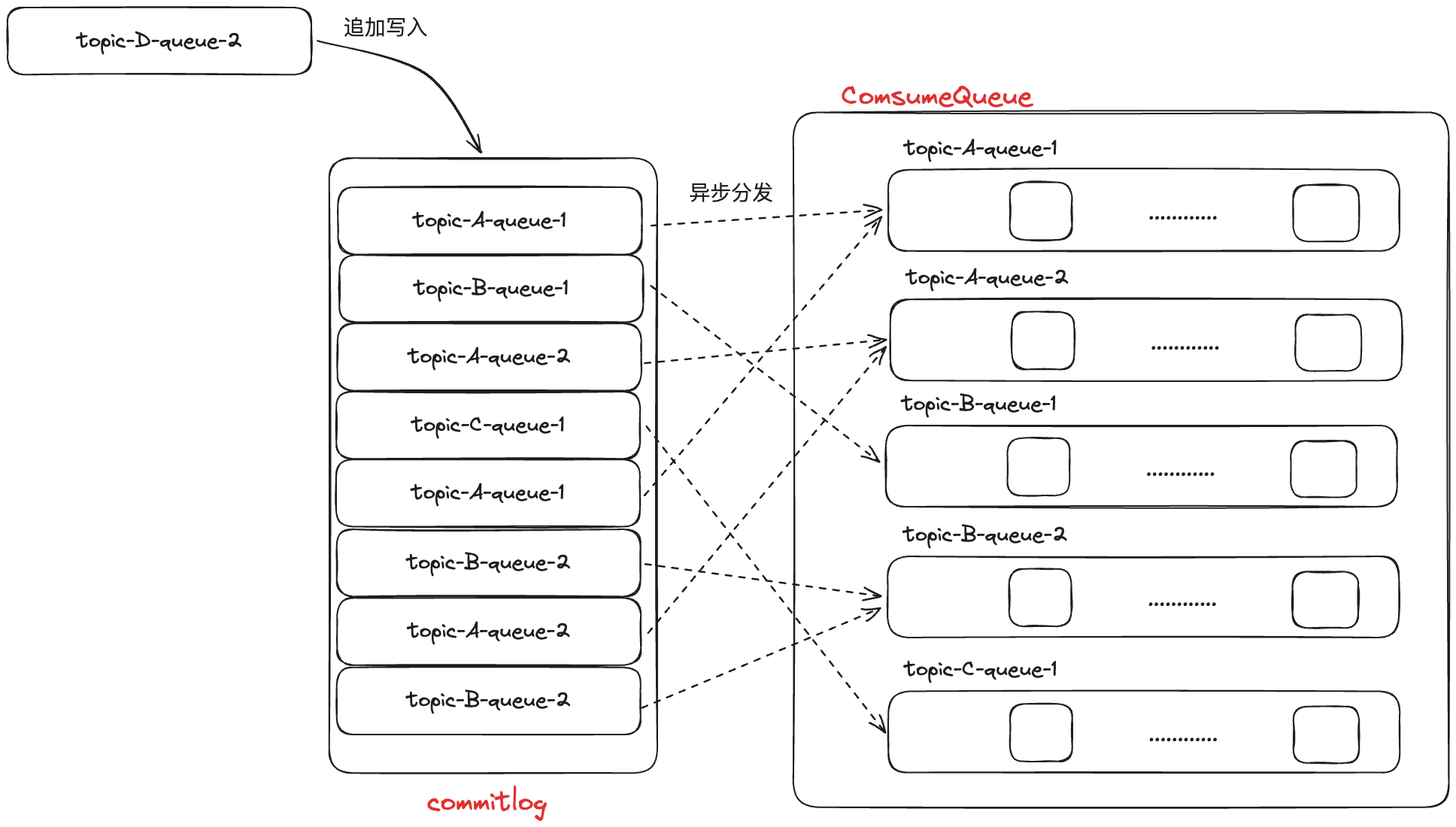
也就是说 RocketMQ 是以 Broker 为单位将此 Broker 收到的所有消息放到一个文件中(当 commitlog 超过 1G,就会新起一个 commitlog) 然后再以 Topic + 队列 维度,存储 ConsumeQueue,消费者具体是通过 ConsumeQueue 得到消息的真实物理地址,再去访问 commitlog 获取消息,所有 ConsumeQueue 可以理解为消息的索引。 每条消息存储至 commitlog,都会在对应的 ConsumeQueue 生成一条记录,因此这个索引也叫做稠密索引。
Kafka 的消息存储
Kafka 和 RocketMQ 一样,Topic 下也分了多个队列提高消费的并发度,但是在 Kafka 中不叫队列,叫分区(Partition)。 Kafka 对消息存储和 RocketMQ 不一样,它是以 Partition 为单位来存储消息的:

从图中可以看到,每个 Topic 的每个分区都会拥有自己的消息文件,且对应的会有索引文件(还有一个时间索引文件,这里不再赘述),它们的文件名一样,后缀有所不同:

都以文件存储的第一条消息的 offset 作为文件名,当一个文件写满会新起一个文件。 不同分区的消息是顺序写入到对应的文件中的,也就是在存储上,同 Topic 且同分区的消息被存储到一个文件中,这跟 RocketMQ 的混合存储是完全不一样的。并且索引文件的设计也不一样,Kafka 不会为每条消息都对应生成一个索引,而是每隔几条消息再创建一条索引,这样能节省存储空间,能在内存中保存更多的索引,这样的索引叫做稀疏索引。
稠密索引的查找逻辑我们很清晰,那稀疏索引是如何查找对应的消息呢?
首先通过 offset
找到对应的索引文件,再通过二分法遍历索引文件找到离目标消息最近的索引,再利用这个索引内容从消息文件找到最近这条消息的位置,再从这个位置开始顺序遍历消息文件找到目标消息。
这样一次寻址的时间复杂度是 O(log2n) + O(m),其中 n
为索引文件中的索引个数,m 为索引的稀疏程度。 相比之下,RocketMQ
的消息寻址则是根据消息
offset,直接计算消息在索引中的实际位置(索引长度固定,位置就是offset * len),然后得到消息在
commitlog 中的物理位置以及消息长度,直接从 commitlog
中获取消息,一次寻址的时间复杂度为 O(1)。
这其实就是时间和空间的权衡了,Kafka
用更少的空间就需要花费更多的时间,而 RocketMQ
用的时间更少却花了更多的空间。没有对错,只有各自权衡利弊,选择最适合的。
其实 Kafka
索引的二分查找并不是朴素的二分查找,而是经过工程优化冷热分区的二分查找。
在操作系统中,文件的读取会先经过 PageCache
缓存一道。如果按照正常的二分查找,那么需要读取索引的头和尾内容,尾的内容是最新写入的,很有可能已经在
PageCache 了,而头的内容可能是很久之前的,很大概率不在 PageCache
中,因此需要从磁盘加载读取到 PageCache。
而内存的资源是有限的,操作系统会通过类 LRU
机制淘汰内存,当内存不足,很有可能因为加载这些很久以前的数据,导致内存中一些最近的
PageCache 被置换到内存,而最近的 PageCache
的消息正常而言是近期会被消费者读取消费的,但这些消息又被挤出了内存,这样一来就造成缓存污染,对性能就不好了;并且按照一般的逻辑,消费者要拉取的消息肯定是在索引文件的尾部,也就是最近写入的,而不是时间久远的头部,从头部查找意义不大。

因为 Kafka 给索引文件做了冷热分区,修改过的二分是先二分查找热区,如果查不到再从冷区开始,由于热区的数据本身都已经在 PageCache 中,因此对缓存友好,不会污染缓存,且很大可能性能找到对应的消息。

对比 Rocket 和 Kafka
从上文来看,两者的相似之处挺多,比如都有对应的索引文件、消息都是追加写入,都是先通过索引再找到消息等等。 但,不同点在于 RocketMQ 是将不同的 Topic 消息都混合存储到一个文件,而 Kafka 则是以分区为单位存储文件。 相比之下 Kafka 的存储结构在数据复制和迁移上更加灵活,迁移一个分区直接拷贝文件就行了,而 RocketMQ 由于一个文件混合存储了所有的 Topic 的信息,因此很不灵活。
从性能来看,它们之间这样的设计有什么显著的区别吗?
RocketMQ 将所有的消息都追加顺序写入到 commitlog 这个文件中,因此它是顺序写,且消费者按序获取最新的消息,虽然不同消费者并发消费时按时拉取消息不是完全按照顺序读取的,但是从整体来看也近似于顺序读。

Kafka 其实也遵循这个规律,对于每个 Partition 文件来说,消息都是顺序追加写入,遵循顺序写;对于消费而言,每个分区都是顺序读,但这一切都得在少量 Topic 和少量 Partition 的前提下。 想象一下,如果一个 Broker 中有海量的 Topic 或者 Partition,那么对于 Kafka 而言就需要增加海量的消息文件,那么不同的 Partition 消息的写入意味着需要频繁切换不同文件来写入,对每个文件而言确实是顺序写,但是从全局来看,这是随机写。不同文件之间的存储不能够保证连续,磁盘需要各种寻道,这样一来性能就会显著下降,同理对消息的读取也是一样的,全局来看就是随机读,因为需要切换很多文件来读取消息。 因此海量 Topic 或者 Partiiton 场景下,Kakfa 的性能会显著下降,而 RocketMQ 没有这个烦恼,这是混合存储的好处。