消费者订阅了某个 Topic 后,就能够从 Broker 获取所有关于这个 Topic 的消息,但是有时候并不是有关这个 Topic 的消息都是消费者感兴趣的。
比如拿游戏来举例子,游戏爱好者们都喜欢游戏相关的信息(订阅了游戏 Topic),但是有些喜欢MC、有些喜欢COC,于是乎他们也只想获取他们喜欢的游戏的相关消息,所以需要做消息过滤。
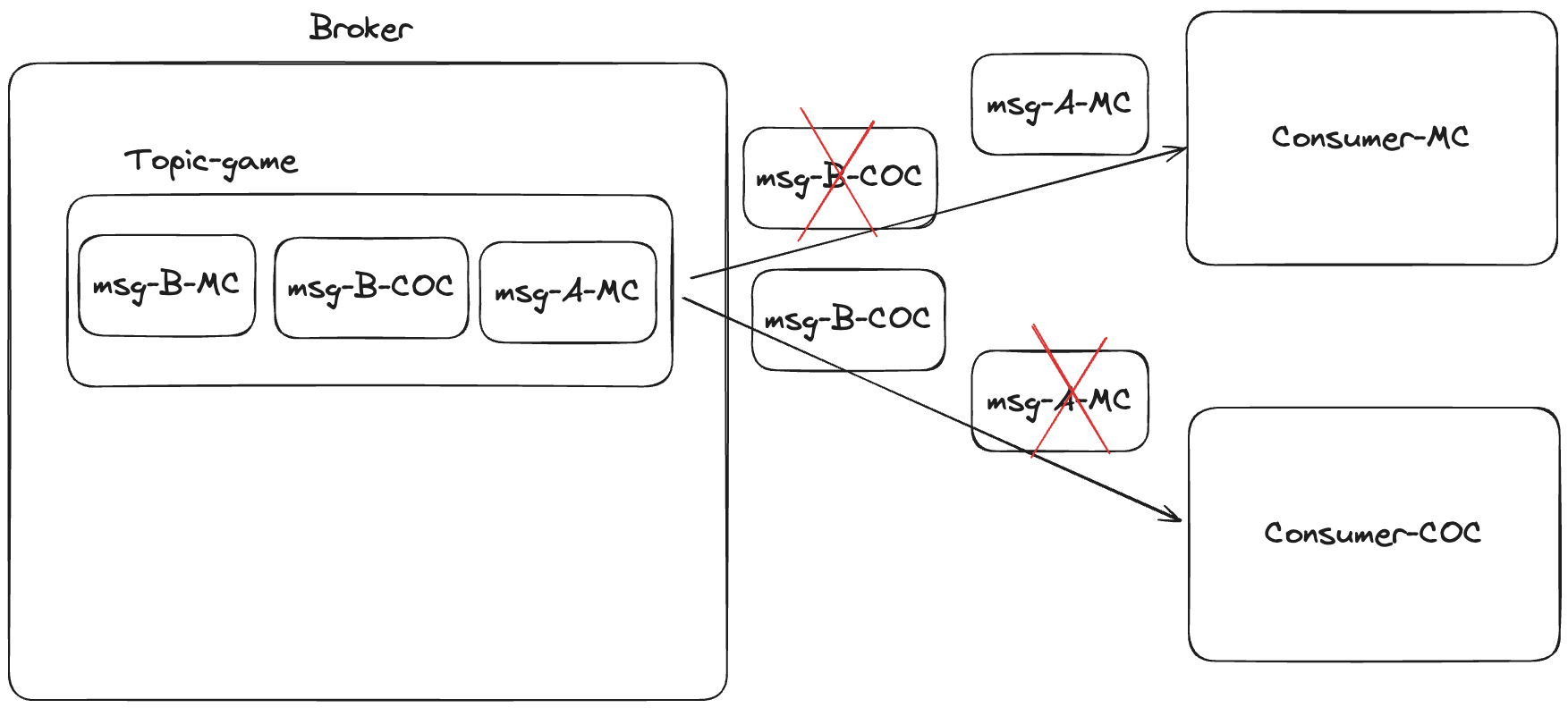
有了过滤机制,消费者就可以避免处理大量对它们而言无用的消息。
这个机制很关键,因为在实际业务场景中,一个主题同时会被多个下游系统订阅,每个下游系统的需求不一样,处理逻辑也大不相同。
所以,虽然都订阅了同一个主题,但是各消费者关注的消息不完全一样,因此没必要让消费者处理主题下的所有消息。
过滤放在 Broker 还是 Consumer?
在明确了消息过滤的意义之后,我们再来思考下,消息过滤逻辑应该放在 Broker 端还是由消费者自己控制呢?
首先,要不要这个消息肯定是由对应的消费者自行决定,这样听起来好像应该把消息一股脑儿地扔给消费者,消费者拿到消息后,看看这个是不是它想要的,如果不是的话就不处理,如果是的话就处理。
但是反过来一想,这样一来消息都已经投递给消费者了,还算减轻消费者的压力吗?不还是让消费者处理大量无用的消息吗?
因此,过滤肯定需要放在 Broker 里。也就是说消费者去拉取消息的时候,Broker 只给消费者想要的消息,自动把不需要的部分过滤了。
这样一来才能高效的减轻消费者的负担,降低消费压力。
Tag 和 SQL
既然已经确定了过滤操作是放在 Broker 里的,那 RocketMQ 支持怎样的过滤方式呢?
官方提供了两种方式,分别是:
- Tag 标签过滤
- SQL 属性过滤
- 自定义过滤(基本上用不到)
Tag 标签过滤
这个也是生产上最常用的消息过滤方式。使用起来也非常简单,就是在生产者构造消息的时候,给消息打一个标记(注意每条消息仅允许设置一个 Tag 标签)。
message.setTags("youyi"); |
仅需一行代码,当前的消息就被打上了标签。然后消费者在订阅 Topic 的时候,指定自己想要接受的 tag 即可。比如:
consumer.subscribe("TopicA", "youyi"); |
然后这个订阅关系会随着心跳发送给 Broker,这样 Broker 就知晓消费者们想要过滤的 Tag 了。当对应消费者去 Broker 拉取消息的时候,就可以过滤掉不要的消息。
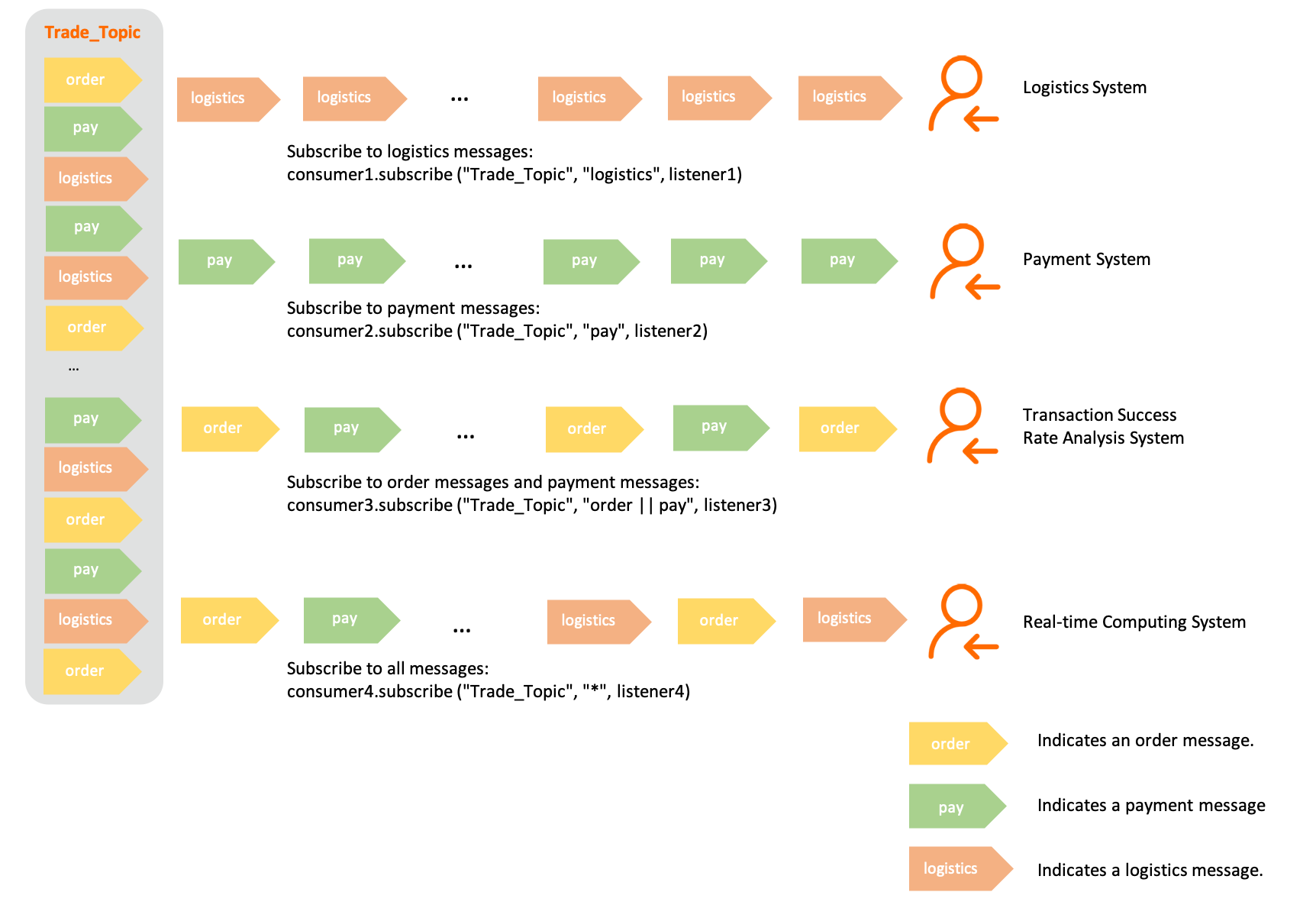
可以看到,交易相关的消息都发往 Trader_Topic 这个主题,其中分别有 order、pay、logistics 这三类消息。然后物流、支付、交易成功率分析、实时计算这四个系统都订阅了 Trader_Topic 这个主题,但并不是所有的消息都需要。比如物流系统仅关注物流消息,支付系统仅关注支付消息,交易成功率分析则是关注订单和支付两个消息,实时计算则是想要处理所有的消息。
这个时候就可以利用 Tag 来给不同的消息打标,区分这三类消息,让对应的系统仅处理对应的子消息即可。
消费者订阅 Tag 有多个规则,从上图我们可以看到:
1)单 Tag 匹配,物流和支付两个系统的订阅:
consumer.subscribe("Trader_Topic", "logistics"); |
2)多 Tag 匹配,交付成功率分析系统的订阅:
consumer.subscribe("Trader_Topic", "order || pay"); |
不同 Tag 之间使用 || 隔开,多个 Tag 之间为或的关系,任意一个 Tag 命中都会被消费者拉取到。
3)全匹配,实时计算系统的订阅,使用*作为全匹配表达式,表示都要。
基本上来说,Tag 过滤已经满足日常的业务需求了,但有些场景下,单凭 Tag 可能还是比较单薄的。
SQL 属性过滤
RocketMQ 提供了一种更高级的过滤方式:SQL 属性过滤。
在发送消息的时候,生产者可以给消息设置属性,属性是一个键值对,然后消费者在订阅时可以设置 SQL 过滤表达式来过滤多个属性。
message.setTag("youyi"); |
上述代码就是生产者在发送消息时给消息设置了一个属性,同时也设置了 Tag。然后消费者在订阅的时候可以指定 SQL 过滤的条件:
consumer.subscribe("TopicA", |
可以看到, SQL 过滤条件比较灵活,不仅可以通过是否有值来过滤的,还可以根据值的内容且能结合多个条件(消息可以设置多属性)一起判断。
SQL 中利用 TAGS 这个属性就能用来判断 Tag 的值,所以 SQL 属性过滤的功能其实是包含了 Tag 过滤的。
SQL 属性过滤是使用 SQL92 语法来作为过滤规则表达式的,官网列举的语法规范图:
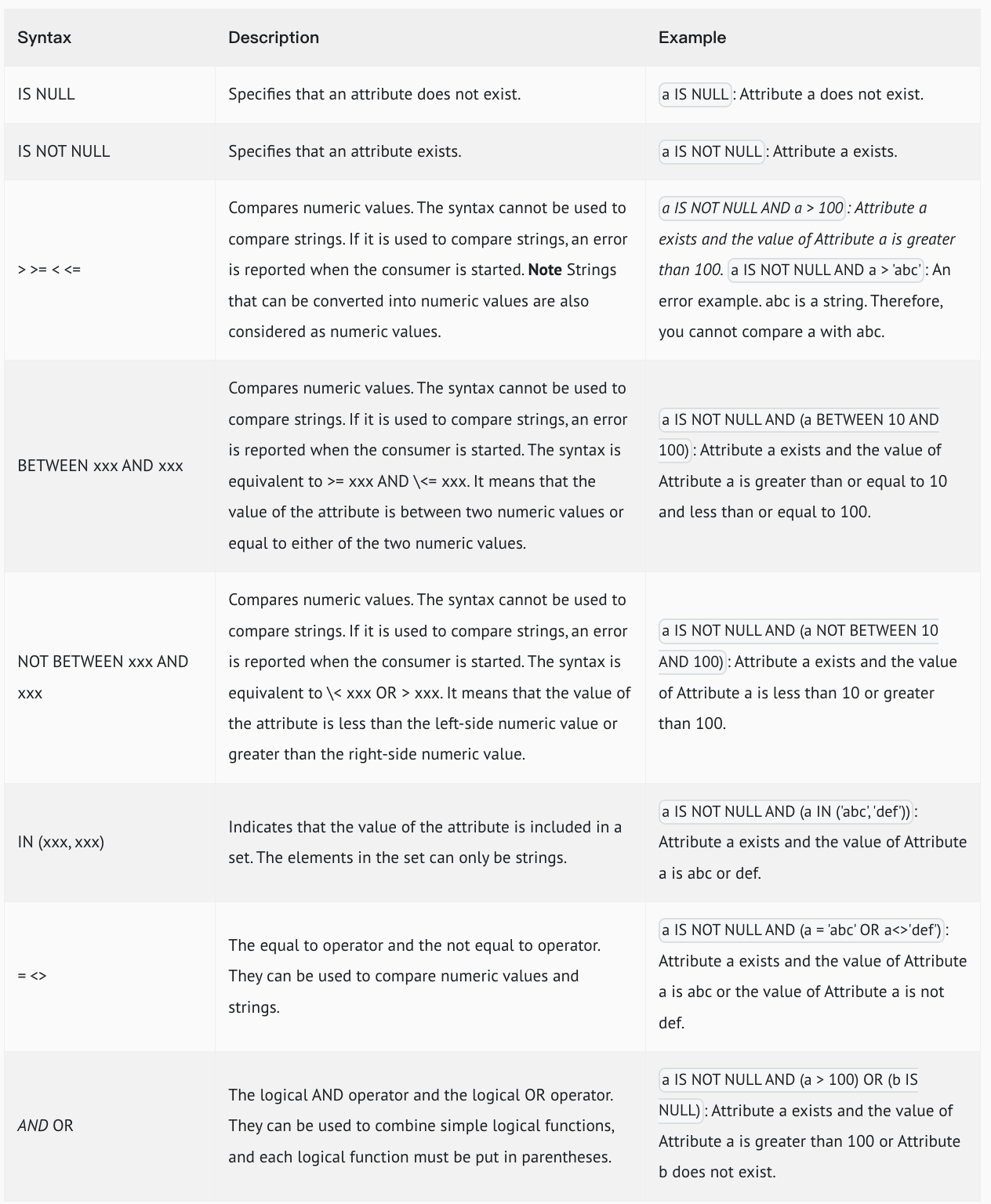
这里需要注意,如果 SQL 表达式计算出现异常,比如类型不一致等情况,消息默认会被过滤,不会被消费者消费。
Tag 过滤原理解析
首先,生产者在构建消息时候设置了 Tag,实际上就是往消息属性设置了一个键值对,key 的值就是 TAGS,也因此 SQL 过滤可以覆盖 Tag 过滤,因为本质上就是通过属性来判断的。
生产者发送消息到 Broker,遵循正常消息的存储逻辑,写到 commitlog 里,且分发到 ConsumeQueue 中,每条消息映射到 ConsumeQueue 的内容都是 commitlog offset、size、taghash
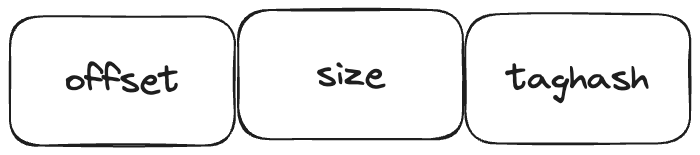
而利用 taghash 就能够快速判断出当前要取的消息打了哪一个 tag,不需要去 commitlog 拉取真正的消息内容再解析,这样就比较高效的完成了 tag 的过滤。
而 Broker是如何得知当前来拉消息的消费者订阅的是哪个 Tag?
前面我们提到过,是从消费者定时给 Broker 的心跳包里面知晓的,消费者启动后就会定时上报自己的订阅信息给 Broker,订阅信息结构如下:
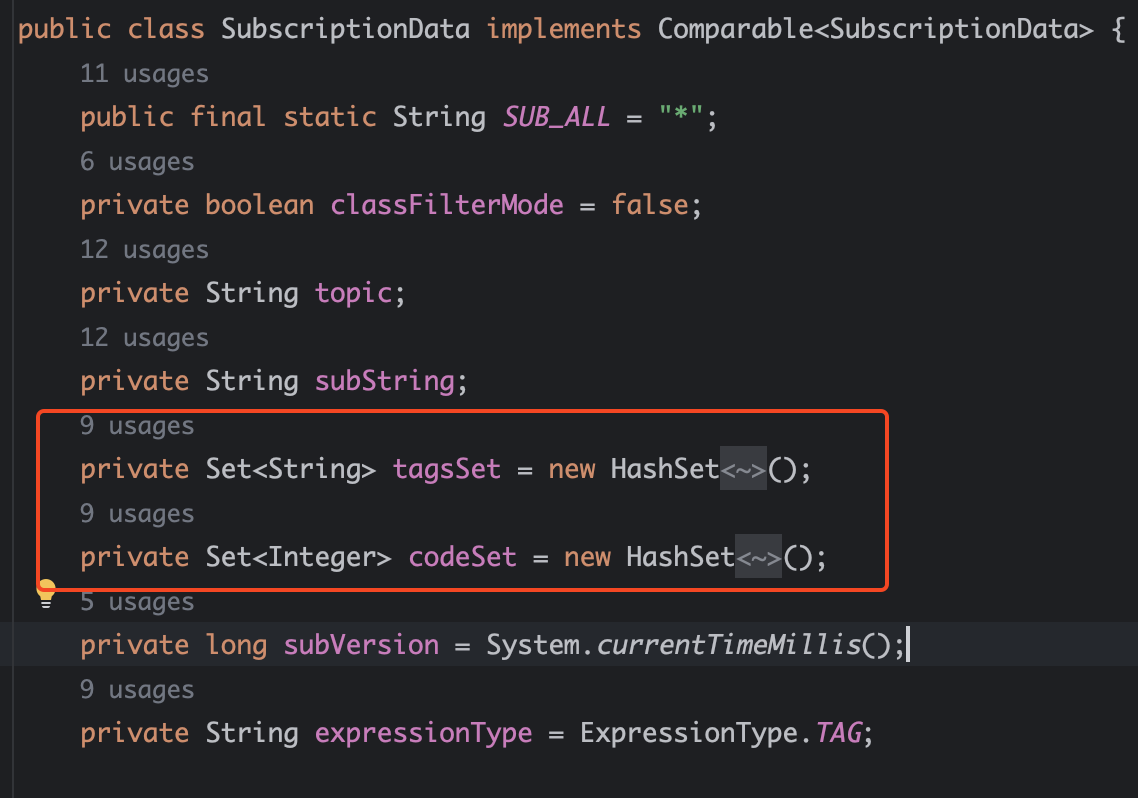
其中的 tagsSet 存储的就是订阅的 tag,而 codeSet 就是 tag 对应的 hash 值,也就是 ConsumeQueue 里的 taghash。
所以 Broker 在消费者来拉消息的时候,利用请求的 offset,从 ConsumeQueue 能直接得到消息的 taghash,且本地已经存储了当前消费者的订阅信息,因此无需解析消息体,也无需去索要消费者的订阅值,直接利用 hashcode 对比当前消息是否应该被该消费者拉取。如果 hashcode 不一致,则跳过这条消息已达到过滤的作用。
为什么要利用 taghash 来过滤,不能直接利用 tag 字符来判断吗?
因为 ConsumeQueue 的设计就是定长的,而 tag 字符的长度不能控制,但 hash 的长度是可以控制的 ,所以采用 hash。
哈希是会碰撞的,也就是不同的 tag 可能产生一样的 hash 值,那咋办?
显然,RocketMQ 也考虑到了这一点,当消费者拉取到经过 Broker 过滤的消息后,它还会自己通过 tag 字符判断一遍,以确保过滤那些因为哈希碰撞导致的消息。这样双重过滤下,就能够保证消息被正确过滤了。
SQL 属性过滤原理解析
其实本质上和 tag 过滤一样,差别就在于 SQL 过滤需要从 commitlog 获取消息,然后解析其中的属性,紧接着再做 SQL 匹配,不匹配的消息被过滤,校验通过的消息被消费者拉取到本地。此时因为不会存在 hash 碰撞的情况,所以消费者本地不需要再进行二次校验。
从实现上,我们可以确定的是:SQL 属性过滤的性能比 Tag 过滤差。
首先 SQL 解析比 Tag 直接 equals 对比慢,其实 SQL 属性过滤还需要从高 commitlog 获取消息体,解析里面的属性再对比,而 Tag 过滤直接拿 ConsumeQueue 里面的内容就能够判断,这里又慢了一次。
所以如果要使用 SQL 过滤的话,需要考虑下性能。